This topic explores crucial theories for machine and deep learning, focusing on probability theory and distributions. We’ll cover:
🎯 Favorable outcomes, expected values, frequencies, and complements.
We’ll then build our first probability frequency distribution, getting hands-on with permutations and their real-world applications. We’ll illustrate the differences between variations and permutations:
📊 Graphical explanations
🧮 Mathematical formulas
📖 Real-life examples
These concepts are vital for understanding examples in various fields.
Introduction
Life is full of uncertainties that often lead us to ask questions like: - What’s the best route to take for a journey? - Will it rain tomorrow? - Is it wise to invest in a certain financial product?
These questions require us to predict outcomes, and the methods we use to navigate these uncertainties are rooted in the fields of probability and statistics.
These very principles form the bedrock of machine learning algorithms, enabling them to learn from data, make predictions, and improve over time.
So, what’s probability? 🤔 It’s simply the likelihood of an event occurring. An “event” in probability denotes a specific or a combination of outcomes, like:
🪙 Coin toss results,
🎲 Rolling a four on a dice, or
🏃♂️ Running a mile under 6 minutes.
For example, a coin toss isn’t a single-probability event as it can result in head or tails. We need to assign a probability for each outcome.
The outcomes can be: - “Head > Tail” - “Head = Tail” - “Head < Tail”.
Understanding uncertainty involves measuring and comparing probabilities to know which event is more likely. We represent probabilities numerically.
Probabilities can be percentages or fractions, but we typically express them as numbers between zero and one. For instance, 20% or \(\frac{1}{5}\) will be written as 0.2.
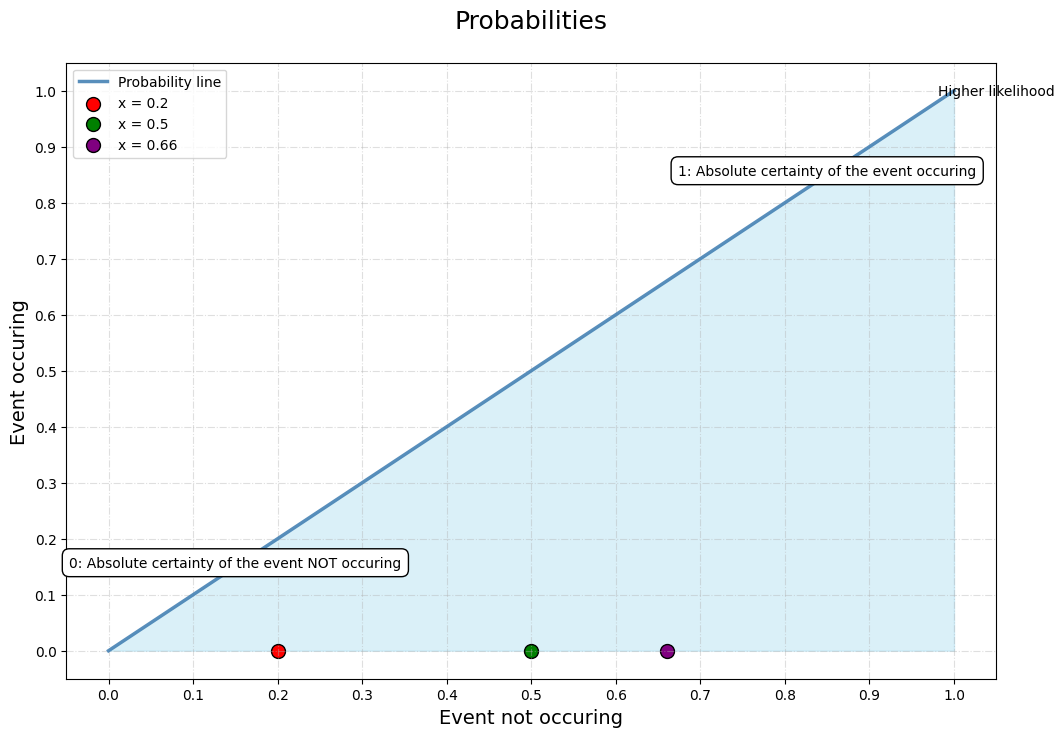
Interpreting probability values: - 1 stands for the absolute certainty of an event, - 0 implies the event will certainly not happen. - Higher values indicate higher likelihoods.
Most events will have probabilities between 0 and 1, so figures like 0.2, 0.5, and 0.66 are common.
Let’s take a look at probabilities of events occuring and not occuring given the chances are equal:
# @title #### Probabilitiesimport matplotlib.pyplot as pltimport numpy as npx = np.linspace(0, 1, 100)y = x plt.figure(figsize=(12, 8))plt.fill_between(x, y, color="skyblue", alpha=0.3)plt.plot(x, y, color="Steelblue", alpha=0.9, linewidth=2.5, label='Probability line')plt.scatter([0.2], [0], color='red', s=100, label='x = 0.2', edgecolors='black')plt.scatter([0.5], [0], color='green', s=100, label='x = 0.5', edgecolors='black')plt.scatter([0.66], [0], color='purple', s=100, label='x = 0.66', edgecolors='black')plt.xlabel('Event not occuring', fontsize=14)plt.ylabel('Event occuring', fontsize=14)plt.title('Probabilities', fontsize=18, pad=25)plt.legend(loc='upper left')plt.text(0.15, 0.15, '0: Absolute certainty of the event NOT occuring', ha='center', fontsize=10, bbox=dict(facecolor='white', edgecolor='black', boxstyle='round,pad=0.5'))plt.text(0.85, 0.85, '1: Absolute certainty of the event occuring', ha='center', fontsize=10, bbox=dict(facecolor='white', edgecolor='black', boxstyle='round,pad=0.5'))plt.text(1.05, 1, 'Higher likelihood', ha='center', fontsize=10, va='center')plt.xticks(np.arange(0, 1.1, 0.1)) plt.yticks(np.arange(0, 1.1, 0.1))plt.grid(True, linestyle='-.', alpha=0.4)plt.show()
As you can see, given all things are equal, the probabilities can be drawn as a straight line.
Favorable Outcomes
Even without exact probabilities, it’s intuitive that some events are likelier. For instance, winning a coin toss is more probable than the lottery. Let’s take a look:
The probability of an event \(A\), denoted as \(P(A)\), is the ratio of desirable outcomes to total outcomes. Preferred or “favorable” outcomes are the results we aim for, while the sample space comprises all possible outcomes.
If event \(A\) is flipping a coin for Heads, it’s the only desired outcome. With two possible outcomes, Heads or Tails, the probability is:
\[P(A)= \frac{1}{2} = 0.5\]
🎲 Six-sided die roll
With a six-sided die, if we wish to roll a \(4\), the desired outcome is \(1\), with \(6\) possible outcomes. This gives a probability of:
\[P(A) = \frac{1}{6} = 0.167\]
If we want a number divisible by 3, i.e., 3 or 6, desired outcomes are 2, giving a probability of:
\[P(A) = \frac{2}{6} = 0.33\]
🎟️ Winning the lottery
With the lottery, you divide the number of tickets bought by all possible outcomes. Given there are over 175 million outcomes, each ticket’s probability is:
\[P(A)= \frac{1}{175 000 000} = 0.000 000 005\]
Buying more tickets increases the winning probability. Comparing this with a coin toss, the latter is more likely.
Coin
Lottery
🪙
🎟️
0.5
0.000 000 005
Expected Values
The Expected Value in probability is the average outcome if an experiment is repeated 🧪. It can be estimated through multiple trials. The experimental probability is calculated by dividing successful trials by all trials:
The Expected Value of an event \(A\), \(E(A)\), is the anticipated result of an experiment. It’s found by multiplying the event’s theoretical probability \(P(A)\) by the number of trials \(n\).
\[E(A) = P(A) \times n\]
Where:
\(E(A)\) is the expected value of an event \(A\),
\(P(A)\) is the probability that event \(A\) occurs, and
\(n\) is the number of trials.
🃏 Playing cards
For instance, we try to calculate the expected value of taking a “Spade ♠” type card in \(20\) card draws. It is known that the probability of picking a “Spade ♠” suit card (if it is assumed that we choose from a standard set of cards) is \(0.25\) or \(1/4\), because there are \(13\) “Spade ♠” cards out of a total of \(52\) cards.
\[E(A) = 0.25 \times 20 = 5\]
This suggests we expect to draw a spade 5 times, though actual results may vary.
Having understood the concept of expected value in the context of drawing Spades from a deck of cards, let’s now consider a different scenario.
🎯 Bullseye
Imagine playing a game of darts where hitting the bullseye is our event of interest. Let’s say that after practicing, we found that our probability of hitting the bullseye is \(1/3\). If we throw the dart \(20\) times, we can calculate our expected number of bullseyes as follows:
\[E(Bullseye) = \frac{1}{3} \times 20 = 6.67\]
This suggests we expect to hit the bullseye about 7 times, although actual results may vary.
However, the real world often presents us with scenarios that are more complex than a single event. In many cases, we have multiple outcomes, each with its own associated probability. This is where the concept of expected value for numerical outcomes comes into play.
In Numerical Outcomes, the expected value is the sum of each possible outcome multiplied by its respective probability. This is essentially a way to calculate a weighted average of all possible outcomes, where the weight for each outcome is its probability.
\[E(X) = A.P(A) + B.P(B) + C.P(C) + ...\]
Where:
\(E(X)\) is the expected value,
\(A, B, C,\) etc. are possible outcomes, and
\(P(A), P(B), P(C),\) etc. are the probabilities of each outcome.
🎯Archery
To illustrate this, let’s consider an archery target 🎯 with three layers:
Outer Layer (10 points) - 👉 50% probability (0.5)
Middle Layer (20 points) - 👉 40% probability (0.4)
Bullseye (100 points) - 👉 10% probability (0.1)
In practice, these probability values may be based on empirical data or previous observations.
So, if we take a lot of shots, our average expected score per shot is 23 points. (The more tries we take, the closer our average score will get to this expected value)
What is this done for? This is usually useful in forecasting, such as weather prediction, where ranges are given due to inherent uncertainty. However, the results are sometimes equivocal or uninformative.
So far we have look at a single example, what if we have two events occuring at the same time?
Understanding Expected Value (E(A))
Imagine a scenario where you roll two six-sided dice and add the numbers that come up on top. With six potential results for each die, the possible outcomes for the sum, denoted as \(A\), are:
\[A = 🎲(⚀⚁⚂⚃⚄⚅) + 🎲 (⚀⚁⚂⚃⚄⚅)\]
The table below illustrates the sum of the die rolls for each possible outcome:
Die 1 Die 2
⚀ 1
⚁ 2
⚂ 3
⚃ 4
⚄ 5
⚅ 6
⚀ 1
2
3
4
5
6
7
⚁ 2
3
4
5
6
7
8
⚂ 3
4
5
6
7
8
9
⚃ 4
5
6
7
8
9
10
⚄ 5
6
7
8
9
10
11
⚅ 6
7
8
9
10
11
12
In total, there are \(6 \times 6 = 36\) possible outcomes.
The number 7 appears 6 times among these 36 outcomes, which means the probability of the sum being 7 when rolling two dice, \(P(7)\) is \(\frac{6}{36} = \frac{1}{6}\)
The expected value of this scenario, \(E(A)\), is calculated by summing the product of each possible outcome and its probability:
\[E(A) = P(2).2+P(3).3 + ... + P(12).12 = 7\]
This formula gives us the “center” of the probability distribution or the average outcome expected if we were to repeat this dice roll many times. In this case, the expected value is 7.
However, it’s crucial to understand that the expected value being 7 does not mean that 7 is a “likely” outcome. With a probability of only one-sixth, the sum of 7, although the most probable single outcome, is not likely in absolute terms. So, betting on exactly 7 wouldn’t be a reasonable strategy.
\[P[E(A)] = P(7) = 1/6\]
This shows us that probability quantifies the likelihood of each individual event.
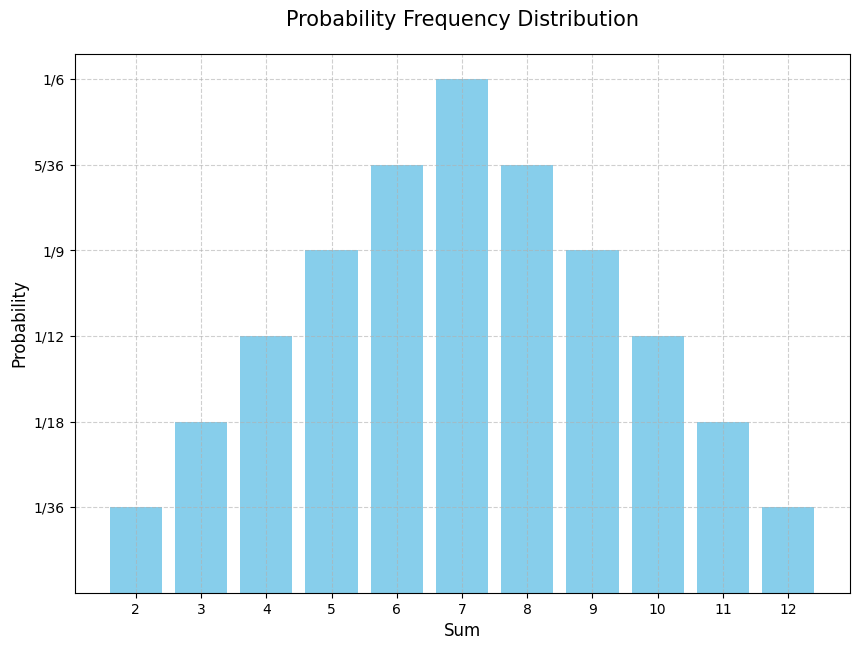
A probability frequency distribution can help visualize all possible outcomes and their corresponding probabilities, highlighting how some outcomes are more probable than others, but no single outcome is “likely” in absolute terms.
Probability frequency distribution
In a probability frequency distribution, we note the frequency of each unique sum from the sample space.
Sum
Frequency
2
1
3
2
4
3
5
4
6
5
7
6
8
5
9
4
10
3
11
2
12
1
For instance, the sum 8 occurs 5 times, so its frequency is 5.
To convert frequencies into probabilities, divide each frequency by the sample size (36). This produces a probability frequency distribution.
Sum
Frequency
Probability
2
1
1/36
3
2
1/18
4
3
1/12
5
4
1/9
6
5
5/36
7
6
1/6
8
5
5/36
9
4
1/9
10
3
1/12
11
2
1/18
12
1
1/36
This distribution can be shown in a table or a graph.
In rolling two dice, the number 7 is likeliest. There are more ways to sum to 7 (1+6, 2+5, 3+4, 4+3, 5+2, 6+1) than to any other number.
Over many trials, 7 will appear more often. So, if guessing a roll’s outcome, 7 is the most reasonable choice based on probability. However, as each roll is an independent random event, a 7 isn’t guaranteed in any particular roll.
This means the outcome of each die does not depend on the outcome of the other die, or on any previous rolls.
For instance, let’s say you roll a pair of dice and get a 3 and a 4. The next time you roll the dice, the chances of getting any specific number (1 through 6) on each die remain exactly the same. Getting a 3 and a 4 on the first roll has no impact on the results of the second roll.
This is the key characteristic of independent random events: - The outcome of one event does not influence the outcome of another.
So in the context of rolling dice, each roll is its own unique event with the same probabilities each time, regardless of what numbers have come up in the past.
Complements
In probability, an event’s complement is everything the event doesn’t include, completing the sample space.
The total probability is the sum of different events’ probabilities.
\[A + A^c = \text{sample space A}\]
Where:
\(A^c \leftarrow \text{Complement: Everything the event is not}\)
The basic concept in probability is that the total of all possible outcomes is always equal to one, indicating 100% certainty that one of the outcomes will occur.
Suppose we have three possible outcomes in an experiment, we can call them A, B, and C.
\(P(A)\) is the probability of A occurring
\(P(B)\) is the probability of B occurring
\(P(C)\) is the probability of C occurring
If we add up the probabilities of all possible outcomes, the sum must equal 1.
In other words, there is 100% certainty that one of A, B, or C will occur.
Let’s clarify this with examples.
🪙 Coin Toss
Consider flipping a coin. The outcomes—heads or tails—are guaranteed. Thus, accounting for these sums the total probability to 1.
\[A \rightarrow (Heads) \ \ B \rightarrow (Tails)\]
\[P(A) + P(B) = 1\]
What happens if \(P(A) + P(B) > 1\)?
A total probability greater than 1 lacks intuitive sense since probabilities denote absolute certainty. An example of this could be when some outcomes simultaneously occur, causing double-counting of outcomes. We’ll handle this with Bayesian notation later.
What happens if \(P(A) + P(B) < 1\)?
If the sum of probabilities is less than 1, we’ve not accounted for some outcomes.
Before proceeding, note that each event has a complement (denoted by \('\)). For instance, complement of \(A\) is \(A'\).
\[A' \leftarrow Complement\]
The complement of a complement is the event itself: \((A')' = A\).
🎲 Rolling a die
Consider rolling a six-sided die intending to roll an even number. The complement is rolling an odd number.
\(A\): ⚀⚁⚂⚃⚄⚅
\(B\): NOT 3
\[A = B\]
Calculating the complement involves taking 1 minus the probability of the event.
All possible outcomes are \(A\), \(B\), and \(C\), and their probabilities must add up to 1
\[P(A) + P(B) + P(C) = 1\]
In this case, \(A\) (the complement of \(A\)) is equal to \(B\) plus \(C\) (\(A' = B + C\)) and the probability is:
\[P(A') = 1 - P(A)\]
Considering the example of rolling a 1, 2, 4, 5, or 6 (i.e., not a 3), the total probability is the sum of these outcomes’ probabilities. Since each outcome has a probability of one-sixth, the sum is 5/6.