What is Distribution in Statistics? 🤔 Distribution is a tool in statistics that outlines the potential values a variable can assume and their frequency. Also known as a probability distribution, it demonstrates how probabilities are dispersed across different outcomes. It helps uncover patterns, randomness, and frequency, essential in theory and practice.
Before we begin, let’s understand the key notation. Notation is a system of symbols representing specific concepts, crucial for clear communication in fields like mathematics and statistics.
In probability, \(Y\) represents an actual event outcome, while \(y\) represents any potential event outcome. The probability notation \(P (Y=y)\) or \(p (y)\) is used to describe the likelihood that a random variable \(Y\) will equal a specific value \(y\).
For instance, consider drawing red marbles \((Y)\) from a bag . If y is a specific count like 3 or 5, we might ask: - What is the probability of drawing 5 red marbles? This can be expressed as \(P (Y=5)\) or \(p (5)\).
Why do we need to know this? ⚠️ Understanding this is crucial as many decisions in fields like data science are based on understanding probabilities. For example, machine learning models often make predictions based on probability.
Now, we’ll proceed with some key definitions in statistical distribution.
Population vs Sample
In data analysis, we differentiate between:
Population data: All the data.
Sample data: A subset of the population data.
Look at this illustration for further clarification:
For example, if an employer surveys a department’s commute methods, that data is the population for that department, but is a sample for the entire company.
Why is it important🤔 This distinction is crucial in statistical distributions as it affects measures of central tendency, spread, and distribution shape. These measures can significantly differ between a population and a sample. The type of data also determines the statistical tests used and how accurately we infer population characteristics.
Types of Probability Distributions
Probability distributions are primarily classified based on the number of possible outcomes:
Discrete distributions: Used when outcomes are finite, like rolling a die 🎲.
Continuous distributions: Used when outcomes are infinite, like measuring time ⏰ or distance 📏.
Discrete Distributions:
Bernoulli Distribution is used in binary classification problems in machine learning, representing a situation with only two outcomes. An example is a model predicting whether an email is spam or not.
Binomial Distribution is used for multi-classification problems, where an event has more than two possible outcomes. An example is a model predicting weather conditions like ‘sunny’, ‘rainy’, or ‘cloudy’.
Continuous Distributions:
Normal Distribution is a commonly observed distribution in many natural phenomena and is often used in machine learning for regression problems. It’s widely used due to its unique statistical properties and its ability to accurately describe many natural occurrences. An example is a model predicting the height of trees, where most predictions cluster around the mean value with rare outliers.
OK, now let’s discuss it in more depth.
Discrete Distribution
Understanding bernoulli and binomial distributions by helping our friend’s business: John Bakery
Image made by Dall-E in ChatGPT 4
Hi new statistician! 👋 John is an owner of a bakery. He needs our help to know how. Are you up for the challenge? 🤔
Likeliness of John’s success in daily sales
So after careful calculation, John said to us that what he called a “successful day” is when he sells 30 or more breads. Let’s see
import gradio as grimport pandas as pd# Define the datasales_data = [ {'Day': 1, 'Breads Sold': 39}, {'Day': 2, 'Breads Sold': 36}, {'Day': 3, 'Breads Sold': 21}, {'Day': 4, 'Breads Sold': 33}, {'Day': 5, 'Breads Sold': 38}, {'Day': 6, 'Breads Sold': 32}, {'Day': 7, 'Breads Sold': 36}, {'Day': 8, 'Breads Sold': 38}, {'Day': 9, 'Breads Sold': 33}, {'Day': 10, 'Breads Sold': 24}, {'Day': 11, 'Breads Sold': 23}, {'Day': 12, 'Breads Sold': 37}, {'Day': 13, 'Breads Sold': 37}, {'Day': 14, 'Breads Sold': 28}, {'Day': 15, 'Breads Sold': 23}, {'Day': 16, 'Breads Sold': 34}, {'Day': 17, 'Breads Sold': 30}, {'Day': 18, 'Breads Sold': 20}, {'Day': 19, 'Breads Sold': 35}, {'Day': 20, 'Breads Sold': 40}, {'Day': 21, 'Breads Sold': 25}, {'Day': 22, 'Breads Sold': 29}, {'Day': 23, 'Breads Sold': 28}, {'Day': 24, 'Breads Sold': 37}, {'Day': 25, 'Breads Sold': 29}, {'Day': 26, 'Breads Sold': 33}, {'Day': 27, 'Breads Sold': 27}, {'Day': 28, 'Breads Sold': 35}, {'Day': 29, 'Breads Sold': 25}, {'Day': 30, 'Breads Sold': 31}]# Convert the data to a pandas DataFramedf = pd.DataFrame(sales_data)# Create a new column "Is Success" based on the conditiondf['Is Success'] = df['Breads Sold'] >=30# Calculate the number of successful days (where "Breads Sold" is 30 or more)successful_days =len(df[df['Breads Sold'] >=30])# Calculate the total number of daystotal_days =len(df)# Calculate the probability of success and convert to percentageprobability_of_success = (successful_days / total_days) *100print(df)# Display the probability as a percentageprint("Probability of success:", probability_of_success, "%")
As we can see above that after reviewing John’s sales data from the past 30 days that the probability of John’s success in daily sales is 60%.
The output can only be success or not
John’s business is a binary problem where the only thing that we care about is whether John’s business is successful on that day or not. For this kind of problem, we can use two distributions: Bernoulli and Binomial.
Single Sample
Bernoulli distribution is really simple: It’s a distribution where the output can only be success or not on only one sample. So we can say that it’s the P for the success and 1 - P for the not success, because the output is binary and the prediction should add up to 1 (prediction of success + prediction of not success = 1). For our friend John, we know that the probability of him failing in achieving his daily sales target is 40% (1 - 0.6 = 0.4). If we put it in a chart it would look like this.
# @title #### John Bakery Chartimport matplotlib.pyplot as pltimport numpy as npimport ipywidgets as widgetsdef plot_bernoulli(p=0.6): variance = p * (1- p) mean = p # Mean of a Bernoulli distribution is equal to its parameter p outcomes = np.array([0, 1]) probabilities = np.array([1-p, p]) plt.bar(outcomes, probabilities, color=['orange', 'green']) plt.xticks(outcomes, ['Fail', 'Success']) plt.ylabel('Probability') plt.xlabel('Outcomes') plt.title('Bernoulli Distribution of John\'s Bakery')# plt.text(0.5, 0.5, 'Mean: {:.2f}'.format(mean), ha='center', va='center', # bbox=dict(facecolor='white', alpha=0.5, boxstyle="round,pad=0.5"))# plt.text(0.5, 0.4, 'Variance: {:.2f}'.format(variance), ha='center', va='center', # bbox=dict(facecolor='white', alpha=0.5, boxstyle="round,pad=0.5")) plt.show()widgets.interact(plot_bernoulli, p=(0, 1, 0.01))
<function __main__.plot_bernoulli(p=0.6)>
Spreading probability to several samples
Bernoulli distribution is focusing on having two possible output on one sample. But how many days that he is likely to be successful in a month? We can use binomial distribution to answer this question. Binomial distribution is a distribution where we can spread the probability of success from bernoulli distribution to several samples. For example, when we work with bernoulli distribution, we only know the probability of success on a single day, but with binomial distribution, we can know the probability of success on several days, how many days that he is likely to be successful in a month, and so on.
Quick About Combination
Let’s simplify first
Before we continue, let’s simplify our scenario first. Imagine if we want to know that we want to know how likely we are successful for exactly two days out of three days, and for now let’s keep it at 50/50 chance of success and failure. We can calculate it like this:
If we succeed on the first day, then if we either succeed on second or third day, it will count to our requirement, we won’t count the condition where we succeed on both second and third day. So for this first scenario we get 2 scenario where we succeed on exactly two days out of three days.
If we fail on the first day, then we need to succeed on both second and third day. So for this second scenario we get 1 scenario where we succeed on exactly two days out of three days.
Below diagram is another way to visualize it, expanded on calculation of when we’re gettting exactly 0 days out of 3, 1 day out of 3, and 3 days out of 3.
image.png
Above concept is called combination, where we want to get exactly y times of success out of n trials, no matter the order (it’s the same if we’re successful on the first day and then the second day with the other way around). We can calculate it using this formula:
\[\binom{n}{y} = \frac{n!}{y!(n-y)!} \]
where \(\binom{n}{y}\) is the notation of combination function and \(n\) is the number of trials and \(y\) is the number of success. So for our calculcation where the number of trials (days) is 3 and the number of success is 2, we can calculate it like this:
Above we already learned about combination, and we need to extend on that function if our likeliness between success and failure is not 50/50. We can do that by multiplying the probability of success with the probability of failure. So the probability function for binomial distribution is:
\[P(y) = \binom{n}{y} p^y (1-p)^{n-y}\]
where \(p\) is the probability of success and \(1-p\) is the probability of failure.
So if we try to plug in the p for our probability of success on 60%, n for the number of trials (days) which is 3, and y for the number of success which is 2, we can calculate it like this:
So the probability for John having exactly 2 days out of 3 days of success is 43.2%.
Take it to graph
Let’s try to plot our previously learned formula to graph!
\[P(y) = \binom{n}{y} p^y (1-p)^{n-y}\]
We’ll let the y to be the x axis while the n will be set to 15 for now and the p will be set to 0.6.
\[P(y) = \binom{15}{y} 0.6^y (1-0.6)^{15-y}\]
import matplotlib.pyplot as pltimport numpy as npfrom scipy.stats import binomfrom ipywidgets import interact, IntSlider, FloatSliderdef plot_binomial_distribution(n, p): x = np.arange(0, n+1) y = binom.pmf(x, n, p) plt.figure(figsize=(10, 6)) bars = plt.bar(x, y) plt.xlabel('Number of Day With Success (y)') plt.ylabel('Probability') plt.title(f'Binomial Distribution - n={n}, p={p}') plt.grid(axis='y')# Adding probability values to each barfor i, bar inenumerate(bars): plt.text(bar.get_x() + bar.get_width() /2, bar.get_height(),f'{y[i]:.2f}', ha='center', va='bottom') plt.show()# Creating an interactive widgetinteract(plot_binomial_distribution, n=IntSlider(min=3, max=30, step=1, value=15, description='n: Number of Trials'), p=FloatSlider(min=0, max=1, step=0.01, value=0.6, description='p: Probability of Success'))
So if we look above graph, the most likely scenario is that John will have 9 days out of 15 days of success, and the probability of that happening is 0.21 or 21%, while it’s nearly impossible for John having 0, 1, 2, and 15 days out of 15 days of success.
Continuous Distributions
Normal Distribution
The Normal Distribution is one of the most commonly found continuous distributions in nature and life. The graph of a Normal Distribution is centered on the mean and if you see below, it’s somewhat shaped like a bell, and that’s why it’s also called the Bell Curve.
So as long as a data, when placed on a graph, forms a bell curve shape, it’s a normal distribution. There is of course a mathematical formula to calculate if a data is a normal distribution or not, but we won’t go into that.
Plotting to graph
import numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport pandas as pdimport ipywidgets as widgetsfrom IPython.display import displayfrom scipy import stats# Global variable to store the commute times dataglobal_commute_times =None# Function to update the plot based on new mean and std_devdef update_plot(mean, std_dev):global global_commute_times # Referencing the global variable# Generating 3000 data points global_commute_times = np.random.normal(mean, std_dev, 3000)# Plotting plt.figure(figsize=(25, 6)) sns.histplot(global_commute_times, kde=True, bins=30, color='blue') plt.title("Distribution of Commute Times") plt.xlabel("Commute Time (minutes)") plt.ylabel("Frequency")# Mean line plt.axvline(x=mean, color='red', linestyle='--') plt.text(mean+0.5, 25, f'Mean: {mean} min', color ='red')# Standard deviation lines with different colors colors = ['green', 'orange', 'purple']for i inrange(1, 4): plt.axvline(x=mean + i*std_dev, color=colors[i-1], linestyle='--') plt.axvline(x=mean - i*std_dev, color=colors[i-1], linestyle='--') plt.text(mean + i*std_dev+0.5, 20, f'Stddev: {i*std_dev:.2f} min', color = colors[i-1]) plt.text(mean - i*std_dev+0.5, 20, f'Stddev: {i*std_dev:.2f} min', color = colors[i-1]) plt.grid(True) plt.show() calculate_statistics(mean, std_dev)def calculate_statistics(mean, std_dev):global global_commute_times# Calculating statistics median = np.median(global_commute_times) variance = np.var(global_commute_times) standard_deviation = np.std(global_commute_times) # Recalculating in case the input std_dev is different within_std_1 = np.sum((global_commute_times > mean - std_dev) & (global_commute_times < mean + std_dev)) within_std_2 = np.sum((global_commute_times > mean -2*std_dev) & (global_commute_times < mean +2*std_dev)) within_std_3 = np.sum((global_commute_times > mean -3*std_dev) & (global_commute_times < mean +3*std_dev)) total_data_points =len(global_commute_times) percentage_within_std_1 = (within_std_1 / total_data_points) *100 percentage_within_std_2 = (within_std_2 / total_data_points) *100 percentage_within_std_3 = (within_std_3 / total_data_points) *100# Displaying the statisticsprint(f"Mean: {mean}")print(f"Median: {median}")print(f"Variance: {variance}")print(f"Standard Deviation: {standard_deviation}")print(f"Percentage within 1 std dev: {percentage_within_std_1:.2f}%")print(f"Percentage within 2 std devs: {percentage_within_std_2:.2f}%")print(f"Percentage within 3 std devs: {percentage_within_std_3:.2f}%")# Creating widgetsmean_widget = widgets.IntSlider(min=0, max=120, value=60, description='Mean:')std_dev_widget = widgets.IntSlider(min=1, max=50, value=10, description='Std Dev:')# Linking widgets to the update functionui = widgets.VBox([mean_widget, std_dev_widget])out = widgets.interactive_output(update_plot, {'mean': mean_widget, 'std_dev': std_dev_widget})# Displaying the widgets and the outputdisplay(ui, out)
On above graph, it’s a graph of data for “commute time”, it’s randomized data but this pattern is mostly what you’ll expect to see in real life. So let’s see what we can gather from this graph:
Mean and median
One of the characteristics of normal distribution is that the mean and median is the same (or at least very close). So as you can see above, the mean is 60 minutes and the median is approximately 60 minutes as well.
In this formula above, \(\sigma^2\) is the variant, \(N\) is the number of data, \(x_i\) is the data, and \(\mu\) is the mean.
So intuitively from the formula you should be able to gather that we just need to calculate the distance of each data from the mean to know how each data is different from the mean, and then we square it that distance so that the negative distance won’t cancel out the positive distance, and then we sum it all up and divide it by the number of data to get the average of the distance, and that’s the variant, the number that tells us how every data is different from the mean.
For above data the variant should be around 100, and can be different each time the data is randomized or you change any parameter.
Standard deviation
Standard deviation is as simple as the square root of the variant.
\[
\sigma = \sqrt{\text{variant}}
\]
Why? Basically because when we’re calculating the variant, we’re squaring the distance of each data from the mean, so to get the original distance we just need to square root it. It helps to visualize the spread of the data, and when it comes to normal distribution, most of the data is within $ - $ and $ + $.
Most of the data will fall in the \(mean \pm 1 \times standard\ deviation\) range
Standard deviation is a measure of how spread out the data is, and in normal distribution most of the data should fall in between of \(mean - 1 \times standard\ deviation\) and \(mean + 1 \times standard\ deviation\) range. You can check on above text of “Percentage within 1 std dev” to confirm that.
68-95-99.7 rule
One of the most common pattern that you’ll see in normal distribution is the 68-95-99.7 rule. It’s a rule that says that :
68% of the data will fall in the \(mean \pm 1 \times standard\ deviation\) range
95% of the data will fall in the \(mean \pm 2 \times standard\ deviation\) range
99.7% of the data will fall in the \(mean \pm 3 \times standard\ deviation\) range.
This number can be slightly different in real life by a bit, but if your data is really a normal distribution, the data should be close to that number.
Exponential Distribution
Exponential distribution is a distribution where the probability of an event occuring is proportional to the length of “waiting time” between the events. The distribution is mostly used in a data where the data is expected to finish in a certain amount of time, like the time between two consecutive arrivals of customers at a store or the time between two consecutive phone calls at a call center.
Let’s see on an example
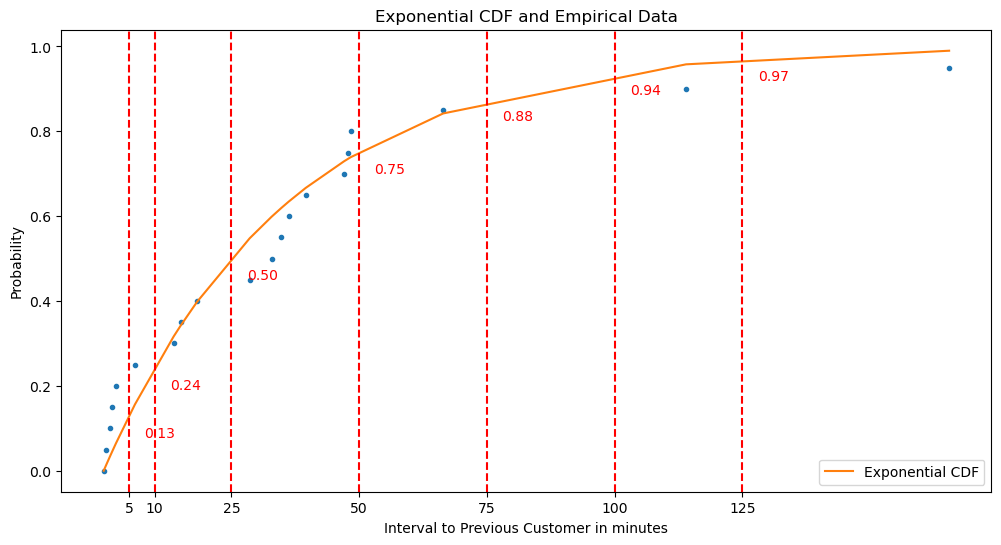
On below graph you can see that graph of the time between two consecutive arrivals of customers at a store. Sometimes the time between one customer to another is short, sometimes it’s long, so below we can check how long we’re supposed to wait for the next customer to arrive.
import numpy as npimport matplotlib.pyplot as pltfrom scipy.stats import exponimport pandas as pd# Select the data for fitting the distributiondata = df['Interval_to_Previous_Customer']# Fit an exponential distribution to the dataloc, scale = expon.fit(data)# Generate sorted data for x-axis of CDF plotx = np.sort(data)# Generate y-axis data for CDF ploty = np.arange(len(x))/float(len(x))# Generate CDF for the exponential distributionexp_cdf = expon.cdf(x, loc, scale)# Create a plotplt.figure(figsize=(12,6))plt.plot(x, y, marker='.', linestyle='none')plt.plot(x, exp_cdf, label='Exponential CDF')plt.title("Exponential CDF and Empirical Data")plt.xlabel('Interval to Previous Customer in minutes')plt.ylabel('Probability')# Add vertical lines and text annotationsx_values = [5, 10, 25, 50, 75, 100, 125]for val in x_values: plt.axvline(x=val, color='r', linestyle='--') prob = expon.cdf(val, loc, scale) # calculate the probability at the x value plt.text(val+3, prob-0.05, f"{prob:.2f}", color='r')# Add x-values to x-axisplt.xticks(x_values)plt.legend()plt.show()# Print the percentage of people coming at each specified intervalfor val in x_values: prob = expon.cdf(val, loc, scale) # calculate the probability at the x valueprint(f"{prob*100:.2f}% of people arrive within an interval of {val} minutes.")
12.97% of people arrive within an interval of 5 minutes.
24.25% of people arrive within an interval of 10 minutes.
50.06% of people arrive within an interval of 25 minutes.
75.06% of people arrive within an interval of 50 minutes.
87.55% of people arrive within an interval of 75 minutes.
93.78% of people arrive within an interval of 100 minutes.
96.90% of people arrive within an interval of 125 minutes.
As you can see, exponential distribution is a distribution where the probability of an event occuring is increasing as the time goes on (we use a variation of exponential distribution where the probability of an event occuring is increasing as the time goes on called Cumulative Distribution Function or CDF, but we won’t go deeper into that). The blue dots is the data gathered from the store, while the orange line is the exponential distribution line, or basically the prediction of the probability of the next customer arriving at that time.
To gather data from above graph is as simple as to check the x axist and then check the y axis for the probability that the event is occuring at that time. For example, if we see above graph at the 5 minutes mark it’s only 13% chance that the next customer will arrive at that time, so maybe we can wait for another 5 minutes, which will increase that chance to be 24%. 15 Minutes after that (25 minutes mark) it’s 50% chance that the next customer will arrive, and so on.

 . If y is a specific count like 3 or 5, we might ask: - What is the probability of drawing 5 red marbles? This can be expressed as
. If y is a specific count like 3 or 5, we might ask: - What is the probability of drawing 5 red marbles? This can be expressed as