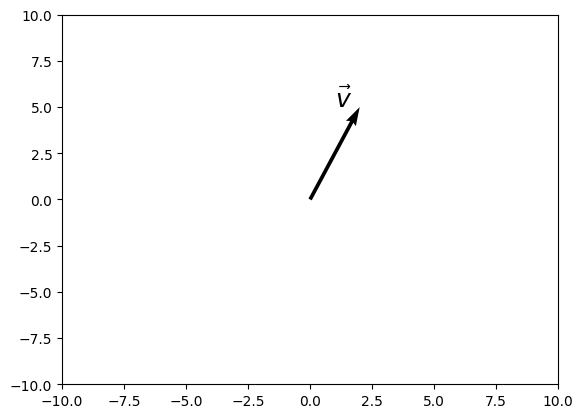
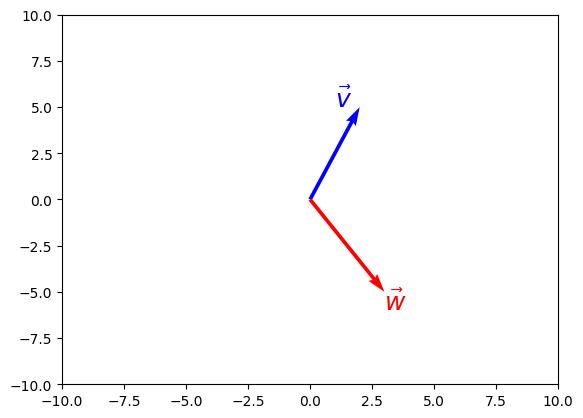
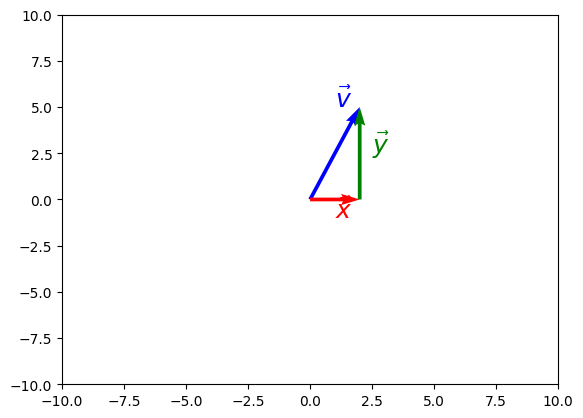
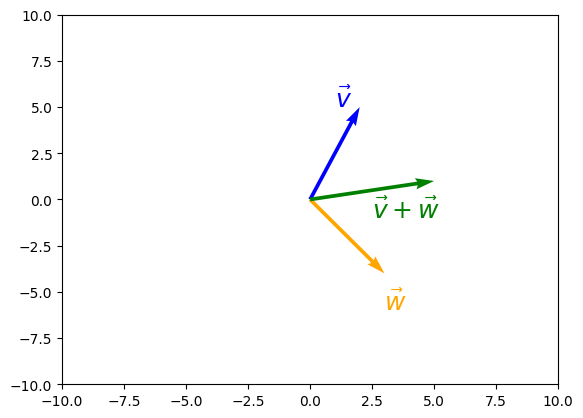
array([-3.3712e-01, -2.1691e-01, -6.6365e-03, -4.1625e-01, -1.2555e+00,
-2.8466e-02, -7.2195e-01, -5.2887e-01, 7.2085e-03, 3.1997e-01,
2.9425e-02, -1.3236e-02, 4.3511e-01, 2.5716e-01, 3.8995e-01,
-1.1968e-01, 1.5035e-01, 4.4762e-01, 2.8407e-01, 4.9339e-01,
6.2826e-01, 2.2888e-01, -4.0385e-01, 2.7364e-02, 7.3679e-03,
1.3995e-01, 2.3346e-01, 6.8122e-02, 4.8422e-01, -1.9578e-02,
-5.4751e-01, -5.4983e-01, -3.4091e-02, 8.0017e-03, -4.3065e-01,
-1.8969e-02, -8.5670e-02, -8.1123e-01, -2.1080e-01, 3.7784e-01,
-3.5046e-01, 1.3684e-01, -5.5661e-01, 1.6835e-01, -2.2952e-01,
-1.6184e-01, 6.7345e-01, -4.6597e-01, -3.1834e-02, -2.6037e-01,
-1.7797e-01, 1.9436e-02, 1.0727e-01, 6.6534e-01, -3.4836e-01,
4.7833e-02, 1.6440e-01, 1.4088e-01, 1.9204e-01, -3.5009e-01,
2.6236e-01, 1.7626e-01, -3.1367e-01, 1.1709e-01, 2.0378e-01,
6.1775e-01, 4.9075e-01, -7.5210e-02, -1.1815e-01, 1.8685e-01,
4.0679e-01, 2.8319e-01, -1.6290e-01, 3.8388e-02, 4.3794e-01,
8.8224e-02, 5.9046e-01, -5.3515e-02, 3.8819e-02, 1.8202e-01,
-2.7599e-01, 3.9474e-01, -2.0499e-01, 1.7411e-01, 1.0315e-01,
2.5117e-01, -3.6542e-01, 3.6528e-01, 2.2448e-01, -9.7551e-01,
9.4505e-02, -1.7859e-01, -3.0688e-01, -5.8633e-01, -1.8526e-01,
3.9565e-02, -4.2309e-01, -1.5715e-01, 2.0401e-01, 1.6906e-01,
3.4465e-01, -4.2262e-01, 1.9553e-01, 5.9454e-01, -3.0531e-01,
-1.0633e-01, -1.9055e-01, -5.8544e-01, 2.1357e-01, 3.8414e-01,
9.1499e-02, 3.8353e-01, 2.9075e-01, 2.4519e-02, 2.8440e-01,
6.3715e-02, -1.5483e-01, 4.0031e-01, 3.1543e-01, -3.7128e-02,
6.3363e-02, -2.7090e-01, 2.5160e-01, 4.7105e-01, 4.9556e-01,
-3.6401e-01, 1.0370e-01, 4.6076e-02, 1.6565e-01, -2.9024e-01,
-6.6949e-02, -3.0881e-01, 4.8263e-01, 3.0972e-01, -1.1145e-01,
-1.0329e-01, 2.8585e-02, -1.3579e-01, 5.2924e-01, -1.4077e-01,
9.1763e-02, 1.3127e-01, -2.0944e-01, 2.2327e-02, -7.7692e-02,
7.7934e-02, -3.3067e-02, 1.1680e-01, 3.2029e-01, 3.7749e-01,
-7.5679e-01, -1.5944e-01, 1.4964e-01, 4.2253e-01, 2.8136e-03,
2.1328e-01, 8.6776e-02, -5.2704e-02, -4.0859e-01, -1.1774e-01,
9.0621e-02, -2.3794e-01, -1.8326e-01, 1.3115e-01, -5.5949e-01,
9.2071e-02, -3.9504e-02, 1.3334e-01, 4.9632e-01, 2.8733e-01,
-1.8544e-01, 2.4618e-02, -4.2826e-01, 7.4148e-02, 7.6584e-04,
2.3950e-01, 2.2615e-01, 5.5166e-02, -7.5096e-02, -2.2308e-01,
2.3775e-01, -4.5455e-01, 2.6564e-01, -1.5137e-01, -2.4146e-01,
-2.4736e-01, 5.5214e-01, 2.6819e-01, 4.8831e-01, -1.3423e-01,
-1.5918e-01, 3.7606e-01, -1.9834e-01, 1.6699e-01, -1.5368e-01,
2.4561e-01, -9.2506e-02, -3.0257e-01, -2.9493e-01, -7.4917e-01,
1.0567e+00, 3.7971e-01, 6.9314e-01, -3.1672e-02, 2.1588e-01,
-4.0739e-01, -1.5264e-01, 3.2296e-01, -1.2999e-01, -5.0129e-01,
-4.4231e-01, 1.6904e-02, -1.1459e-02, 7.2293e-03, 1.1026e-01,
2.1568e-01, -3.2373e-01, -3.7292e-01, -9.2456e-03, -2.6769e-01,
3.9066e-01, 3.5742e-01, -6.0632e-02, 6.7966e-02, 3.3830e-01,
6.5747e-02, 1.5794e-01, 4.7155e-02, 2.3682e-01, -9.1370e-02,
6.4649e-01, -2.5491e-01, -6.7940e-01, -6.9752e-01, -1.0145e-01,
-3.6255e-01, 3.6967e-01, -4.1295e-01, 8.2724e-02, -3.5053e-01,
-1.7564e-01, 8.5095e-02, -5.7724e-01, 5.0252e-01, 5.2180e-01,
5.7327e-02, -7.9754e-01, -3.7770e-01, 7.8149e-01, 2.4597e-01,
6.0672e-01, -2.0082e-01, -3.8792e-01, 4.1295e-01, -1.6143e-01,
1.0427e-02, 4.3197e-01, 4.6297e-03, 2.1185e-01, -2.6606e-01,
-5.8740e-02, -5.1003e-01, 2.8524e-01, 1.3627e-02, -2.7346e-01,
6.1848e-02, -5.7901e-01, -5.1136e-01, 3.6382e-01, 3.5144e-01,
-1.6501e-01, -4.6041e-01, -6.4742e-02, -6.8310e-01, -4.7427e-02,
1.5861e-01, -4.7288e-01, 3.3968e-01, 1.2092e-03, 1.6018e-01,
-5.8024e-01, 1.4556e-01, -9.1317e-01, -3.7592e-01, -3.2950e-01,
5.3465e-01, 1.8224e-01, -5.2265e-01, -2.6209e-01, -4.2458e-01,
-1.8034e-01, 9.9502e-02, -1.5114e-01, -6.6731e-01, 2.4483e-01,
-5.6630e-01, 3.3843e-01, 4.0558e-01, 1.8073e-01, 6.4250e-01],
dtype=float32)