Seq2Seq With RNN
What is Seq2Seq
User: Siapa penemu lampu bohlam?
AI: Penemu lampu bohlam adalah Thomas Alva Edison. Ia merupakan seorang penemu dan pengusaha berkebangsaan Amerika Serikat. Edison menemukan lampu pijar yang praktis pada tahun 1879.
Familiar with above text? Sequence-to-sequence, or seq2seq for short, is a model architecture that receive an input of a sequence of words and output another sequence of words. Sequence, to another sequence of words, seq-to-seq, Seq2Seq! 😀.
Overall Architecture
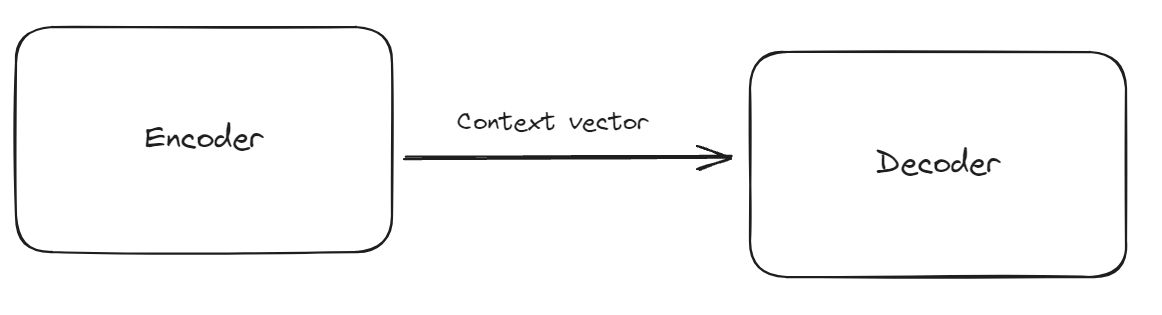
The architecture of seq2seq model is divided into two parts, the encoder and the decoder. We’ll describe each part in detail below, but for now you we can at least describe which sequence does encoder and decoder handle:
- Encoder uses the many-to-one RNN architecture
- Decoder uses the one-to-many RNN architecture
- Context vector is the last hidden state of the encoder, that will bridge the encoder and decoder
You can see below diagram to better understand the intuition:

The history of why we use Seq2Seq for NLP

The intuition behind why we use seq2seq is simple: we can visualize every sentence as a sequence, the input for can be variable length, and the output can also be variable length.
Imagine we want to translate below sentence:
After several minutes of waiting, Afista’s patience grow thinner and he leaves
We need to read the words letter by letter, after we understand the whole sentence, we can translate it to another language. So, if you read above diagram, basically we can intuitively breakdown the concept like how we approach the problem in real life:
- Encoder will read the input sequence letter by letter, try to understand the whole sentence
- The context vector will be the representation of that understanding that the encoder has and will be passed to the decoder
- Decoder will “read” the context vector and generate the output sequence letter by letter
And the reason why we use encoder-decoder architecture is because we want the capability to input different length of sequence and output different length of sequence, such as:
Input: Hi, can you tell me the time in Jakarta right now?
Output: Yes, the time in Jakarta right now is 10:00 AM, do you need anything else?
We can see that the input has 12 words, while the output has 16 words. If we use the traditional RNN architecture encoder-decoder, we can’t do that because the input and output must have the same length.
The Bridge Between Encoder and Decoder: Context Vector
Before we dive deeper to what is encoder and what is decoder, it’s easier for us to try to understand context vector first.
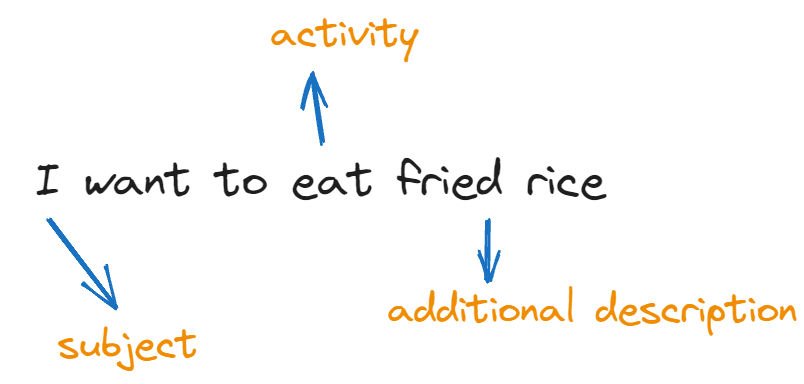
Context vector is basically a way to compress every information from an input to a single vector. Imagine if we have a context vector that has 3 dimensions such as:
\[ [.., .., ..] \]
We may fill these 3 dimensions with 3 different type, such as: The subject in the input, the activity that the subject will be doing, and additional description that might be needed to expand on the activity. Of course it’s a really simplified intuition, in reality the dimension of a context vector might be hundreds or even thousands.
So in human word, several examples of how an input converted to context vector might be look like so:
I want to eat fried rice -> [I, eat, fried rice]
You want to drink orange juice -> [You, drink, orange juice]
He wants to write a novel -> [He, write, a novel]In our fictional scenario, we only want to have this pattern to translate “[subject] want/wants to [activity] [additional description]” so above context vectors would be enough.
Then of course we know that our machine learning model only understand numbers, so they might assign above dimensions with below dictionaries
subject:
0 - I
1 - You
2 - He
activity:
0 - eat
1 - drink
2 - write
additional description:
0 - fried rice
1 - orange juice
2 - a novelSo our human words will become below context vector!
I want to eat fried rice -> [I, eat, fried rice] -> [0, 0, 0]
You want to drink orange juice -> [You, drink, orange juice] -> [1, 1, 1]
He wants to write a novel -> [He, write, a novel] -> [2, 2, 2]So context vector is summary of the entire input
Encoder and decoder
Encoder
From above diagram you can see that encoder is a many-to-one RNN architecture, which means that it will receive a sequence of words as an input, and output a single vector as a context vector. The encoder, like our intuition above, will read the input sequence letter by letter, and try to “understand” the whole sentence, then output a single vector that represents it’s understanding.
Of course the word itself is already preprocessed to tokenized form, then passed to a word embedding layer to convert it to a vector then passed to the encoder.
Just like our previous example
I want to eat fried rice -> [I, eat, fried rice] -> [0, 0, 0]
You want to drink orange juice -> [You, drink, orange juice] -> [1, 1, 1]
He wants to write a novel -> [He, write, a novel] -> [2, 2, 2]We can see on above example that the input is a sequence of words that is summarized in a single vector. For more realistic example, we will learn more on later section using Google Sheets.
So what is context vector when we’re talking about encoder? It’s the final hidden state of the encoder.
Decoder
For decoder it’s really simple, we use one-to-many RNN architecture, which means that it will receive the context vector that was produced by the encoder, and output a sequence of human language. From our intuition above, we can see that the decoder will “read” the context vector and will be the “translator” that will generate the output sequence letter by letter.
- The context vector will be passed as the initial hidden state of the decoder, and the first input of the decoder will be a special token that indicates the start of a sentence:
<bos>(beginning of sentence) - The decoder then will produce the first word of the output sequence, then the first word will be passed as the input of the next time step, and the decoder will produce the second word of the output sequence, and will feed the second word as the input of the next time step, and so on until the decoder produce a special token that indicates the end of a sentence:
<eos>(end of sentence)