Deep Learning consists of neural networks with many layers. The layers are connected to each other and each layer has a weight. The weight is used to calculate the output of each layer. The output of the previous layer is used as the input of the next layer. The output of the last layer is the output of the model.
So what is neural networks?
Neural Networks
Neural Networks consists of neurons. Each neuron has inputs, weights, bias, an activation function, and an output.
from fastbook import*# Draw neurons with multiple inputs and weightsgv('''z[shape=box3d width=1 height=0.7]bias[shape=circle width=0.3]// Subgraph to force alignment on x-axissubgraph { rank=same; z; bias; alignmentNode [style=invis, width=0]; // invisible node for alignment bias -> alignmentNode [style=invis]; // invisible edge z -> alignmentNode [style=invis]; // invisible edge}x_0->z [label="w_0"]x_1->z [label="w_1"]bias->z [label="b" pos="0,1.2!"]z->output [label="z = w_0 x_0 + w_1 x_1 + b"]''')
The final equation is still linear, it doesn’t differ from a single layer.
By being linear the final equation would still be a straight line.
To introduce non-linearity, we need to add an activation function.
\[
a^{[0]} = g(z^{[0]})
\]
from fastbook import*# Draw neurons with multiple inputs and weightsgv('''z[shape=box3d width=1 height=0.7]bias[shape=circle width=0.3]// Subgraph to force alignment on x-axissubgraph { rank=same; z; bias; alignmentNode [style=invis, width=0]; // invisible node for alignment bias -> alignmentNode [style=invis]; // invisible edge z -> alignmentNode [style=invis]; // invisible edge}x_0->z [label="w_0"]x_1->z [label="w_1"]bias->z [label="b" pos="0,1.2!"]z->a [label="z = w_0 x_0 + w_1 x_1 + b"]a->output [label="a = g(z)"]''')
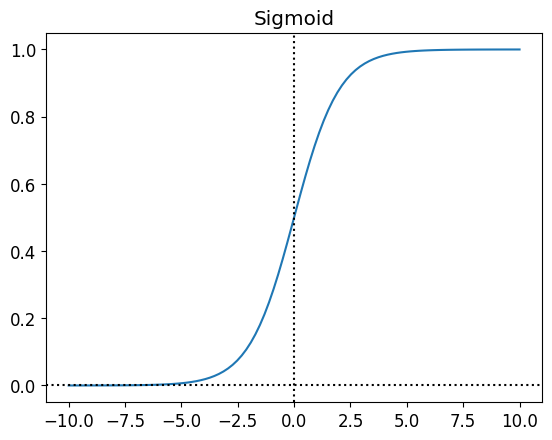
There are many activation functions, but the most common ones are: - Sigmoid \[
g(z) = \frac{1}{1 + e^{-z}}
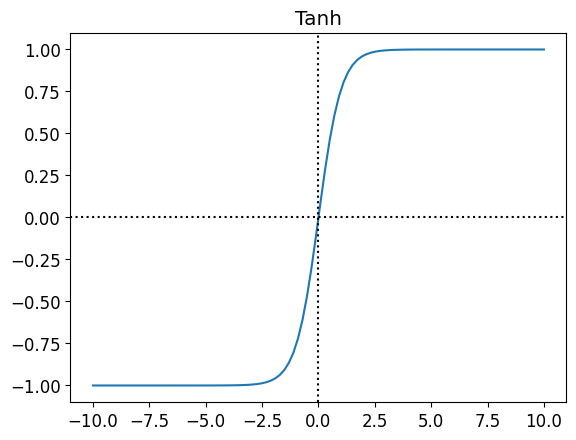
\] - Tanh \[
g(z) = \frac{e^z - e^{-z}}{e^z + e^{-z}}
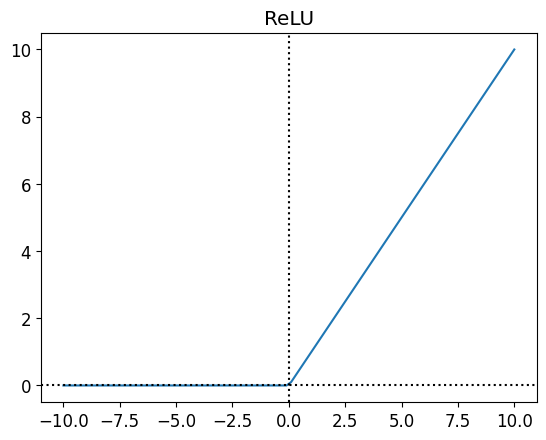
\] - ReLU \[
g(z) = max(0, z)
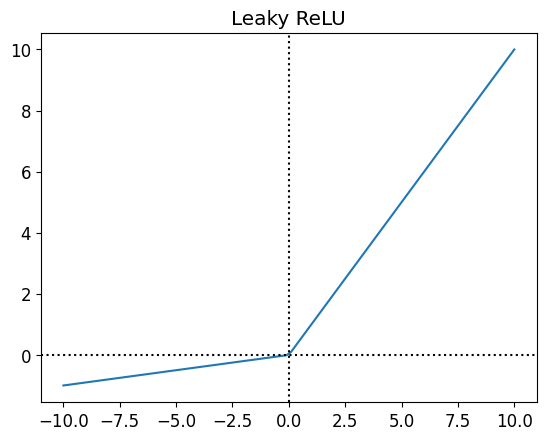
\] - Leaky ReLU \[
g(z) = max(0.01z, z)
\]
The decision to use which activation function depends on the problem. - Sigmoid used to be the most popular activation function, but it has a problem called vanishing gradient. It means that the gradient becomes very small and the model doesn’t learn anymore. - Tanh is similar to sigmoid, but it has a range from -1 to 1. - ReLU is the most popular activation function right now. It is simple and it doesn’t have vanishing gradient problem. - Leaky ReLU is a variation of ReLU. It is used to solve the dying ReLU problem. Dying ReLU is a problem where the neuron doesn’t activate anymore because the input is always negative.
# Draw sigmoid, tanh, ReLU, and Leaky ReLU activation functions using matplotlibimport matplotlib.pyplot as pltimport numpy as npx = np.linspace(-10, 10, 100)sigmoid =1/(1+np.exp(-x))tanh = (np.exp(x)-np.exp(-x))/(np.exp(x)+np.exp(-x))relu = np.maximum(0, x)leaky_relu = np.maximum(0.1*x, x)# Draw each in a separate plotplt.plot(x, sigmoid)plt.title("Sigmoid")# Draw x and y axes, make it dottedplt.axhline(y=0, color='k', linestyle='dotted')plt.axvline(x=0, color='k', linestyle='dotted')plt.show()plt.plot(x, tanh)plt.title("Tanh")plt.axhline(y=0, color='k', linestyle='dotted')plt.axvline(x=0, color='k', linestyle='dotted')plt.show()plt.plot(x, relu)plt.title("ReLU")plt.axhline(y=0, color='k', linestyle='dotted')plt.axvline(x=0, color='k', linestyle='dotted')plt.show()plt.plot(x, leaky_relu)plt.title("Leaky ReLU")plt.axhline(y=0, color='k', linestyle='dotted')plt.axvline(x=0, color='k', linestyle='dotted')plt.show()
Matrix Representation with Activation Function
Let’s try to add activation function to the previous example
\[
x =
\begin{bmatrix}
x_0 \\
x_1
\end{bmatrix}
\]