Computer Vision

Source: TED Talk
Computers are very good at being consistent and processing numbers. But they’re blind, sure they can show images for us in our monitor, but it cannot directly interact with us like human-to-human interaction. Like giving us feedback or help us monitor our CCTV feed and let us know if something is suspicious. That’s because until the recent age of AI, computers are blind. There are attempts to emulate vision, which is what the field Computer Vision is. Let’s start with how we see the world.
How humans see the world
Have you ever think about what’s happening when we see with our eyes ? Look around and what do you see ? A chair, a table, a computer, a smartphone and many others. How do we know that object is indeed a chair or A table ?
If we think about it, back when we were younger, our parents or other people would point out an object and call out it’s name. Sometimes it’s explicit, for example “that’s a green apple”. Sometimes it’s implicit, “let’s sit at the chair over there”. We will then observe the object, take notes and give it an appropriate label. So we identify an object and give it a label.
How do computers see the world ?
The story began back in 1959 where a group of neurophysiologists showed a cat an array of images, attempting to correlate a response in its brain. They discovered that it responded first to hard edges or lines, and scientifically, this meant that image processing starts with simple shapes like straight or curved edges, not objects. Interesting isn’t it ?
How Computer Vision works
Which one is correct ? Well, apparently both of them, the field of computer vision does follow how our brain works, so we also start with the edges before the object, but it’s happening so fast that we don’t even think about it anymore.
In any case, we are not going to discuss how our brain works in relation to computers, we are here to learn about the application of computer vision to enable computers to see.
Two essential technologies are used to accomplish this: - A type of machine learning called deep learning, which we already covered earlier - A convolutional neural network (CNN), which we are going to learn next
Convolutional Neural Network (CNN)
A Convolutional Neural Network (CNN) is a type of artificial neural network (ANN), that was designed for image recognition using a special type of layer, aptly named a convolutional layer, and has proven very effective to learn from image and image-like data. Regarding image data, CNNs can be used for many different computer vision tasks, such as image processing, classification, segmentation, and object detection.
In total, there are three main types of CNN layers:
- Convolutional layer
- Pooling layer
- Fully-connected (FC) layer

Source: Research Gate
From the picture above, the input image goes through the convolution process in the convolution layer and the output is a feature map. The feature map then went through subsampling in the Pooling layer (subsampling layer) which effectively reduces the size by half, and so on, until it reaches the final layer which is a fully connected layer where the input is processed to return a probability between 0 and 1. With each layer, the CNN increases in its complexity, identifying greater portions of the image. Earlier layers focus on simple features, such as colors and edges. As the image data progresses through the layers of the CNN, it starts to recognize larger elements or shapes of the object until it finally identifies the intended object.
Note: ANN is actually the same Neural Network that we learn earlier, so we’ll use the term Neural Network or NN going forward.
Application of Computer Vision
Source: AI Index Stanford



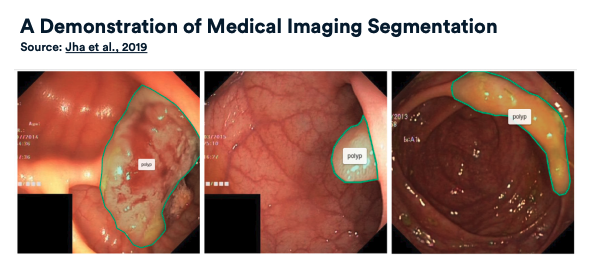


Source: MIT 6.S191: Convolutional Neural Networks
