Elasticsearch (Source: technocratsid.com)
Data modeling is a design process that defines the structure, organization, and types of data, optimizing the way data is stored, organized, and accessed. The importance of data modeling lies in its ability to optimize data retrieval, maintain data integrity, and improve overall performance, especially with vast amounts of data.
Importance of Data Modeling
Understanding data modeling in Elasticsearch is crucial:
- Migration Complexity: Moving from a relational database to Elasticsearch is not a simple data shift due to different data structures and query mechanisms.
- Efficient Searching and Analysis: To fully use Elasticsearch’s capabilities, you need to structure your data for efficient searching and analysis.
- Normalization vs Search-Oriented Modeling: Unlike database normalization in relational databases, Elasticsearch often involves denormalization to speed up search operations.
Elasticsearch’s Schema
Elasticsearch provides a flexible yet consistent schema:
- Schemaless Data Insertion: You can insert data into an index without pre-defining the schema.
- Flexible But Consistent Schema: Once a schema is formed, existing attributes can’t be changed, only new ones can be added. This differs from MongoDB’s fully dynamic schema.
Primary Key
The primary key in Elasticsearch is unique:
- Mandatory ID: An ID is required when creating a document to uniquely identify it in an index.
- Fixed ID Field: The primary key is always the
_id field.
- Single Field and String Type: The primary key can’t consist of more than one field, and the
_id type is always a string.
Data Model Perspectives
In Elasticsearch, consider these perspectives when creating a schema index:
- Embedded Document: Used for one-to-one or one-to-many relationships, this model nests documents within another for faster queries.
- Reference Document: Each document stands alone and references others by their IDs. This is used for many-to-many relationships or large data.
Embedded vs Reference
| If there’s a strong dependency between documents or if the embedded document is always needed when retrieving the main one. |
If the documents can stand alone, can be manipulated directly, or if the reference document is not always needed when retrieving the main one |
The choice depends on your specific use case and data nature.
Data Types
Elasticsearch supports numerous data types. Here are some basic ones:
Basic Data Types
| binary |
Base64 encoded string |
| boolean |
True or false |
| date |
Date and time (up to millisecond) |
| date_nanos |
Date and time (up to nanosecond) |
| ip |
IPv4 or IPv6 |
| keyword |
Structured text (e.g., id, email, hostname, zipcode) |
| text |
Text |
| version |
Semantic version data |
Numeric Data Types
| long |
64-bit integer (-\(2^{63}\) to \(2^{63} - 1\)) |
| integer |
32-bit integer (-\(2^{31}\) to \(2^{31} - 1\)) |
| short |
16-bit integer (-32768 to 32764) |
| byte |
8-bit integer (-128 to 127) |
| double |
64-bit IEEE 754 floating point |
| float |
32-bit IEEE 754 floating point |
| half_float |
Half of a 16-bit IEEE 754 floating point |
| scaled_float |
Floating point stored in long |
| unsigned_long |
64-bit integer (0 to \(2^{64} - 1\)) |
Range Data Types
| integer_range |
Range of min and max integer |
| float_range |
Range of min and max float |
| long_range |
Range of min and max long |
| double_range |
Range of min and max double |
| date_range |
Range of min and max date |
| ip_range |
Range of min and max IP |
Other Data Types
Includes Geopoint, Geoshape, Point, Shape, Rank, Token, and Completion.
Elasticsearch supports many other types, especially for Geospatial data.
Working with Embedded Data Types
When using Elasticsearch, we often work with data in the JSON format, which allows us to have data elements embedded within other elements. These could be objects or arrays. But how does Elasticsearch handle these complex structures?
Behind the scenes: Apache Lucene
Elasticsearch works its magic by using a powerful engine called Apache Lucene. When you give Elasticsearch a piece of data, it takes your JSON and transforms it into a format that Lucene can understand.
Think of it like a translator. You’re speaking in JSON, and Lucene only understands its own language. So Elasticsearch steps in and translates your JSON into ‘Lucenese’.
But there’s a little twist. Lucene’s world is more like a simple dictionary: it’s all about keys and values, and it doesn’t really understand the concept of embedded data types. So when it sees a complex JSON data structure, it needs to flatten it out.
Let’s look at some examples to illustrate how this transformation happens (images):
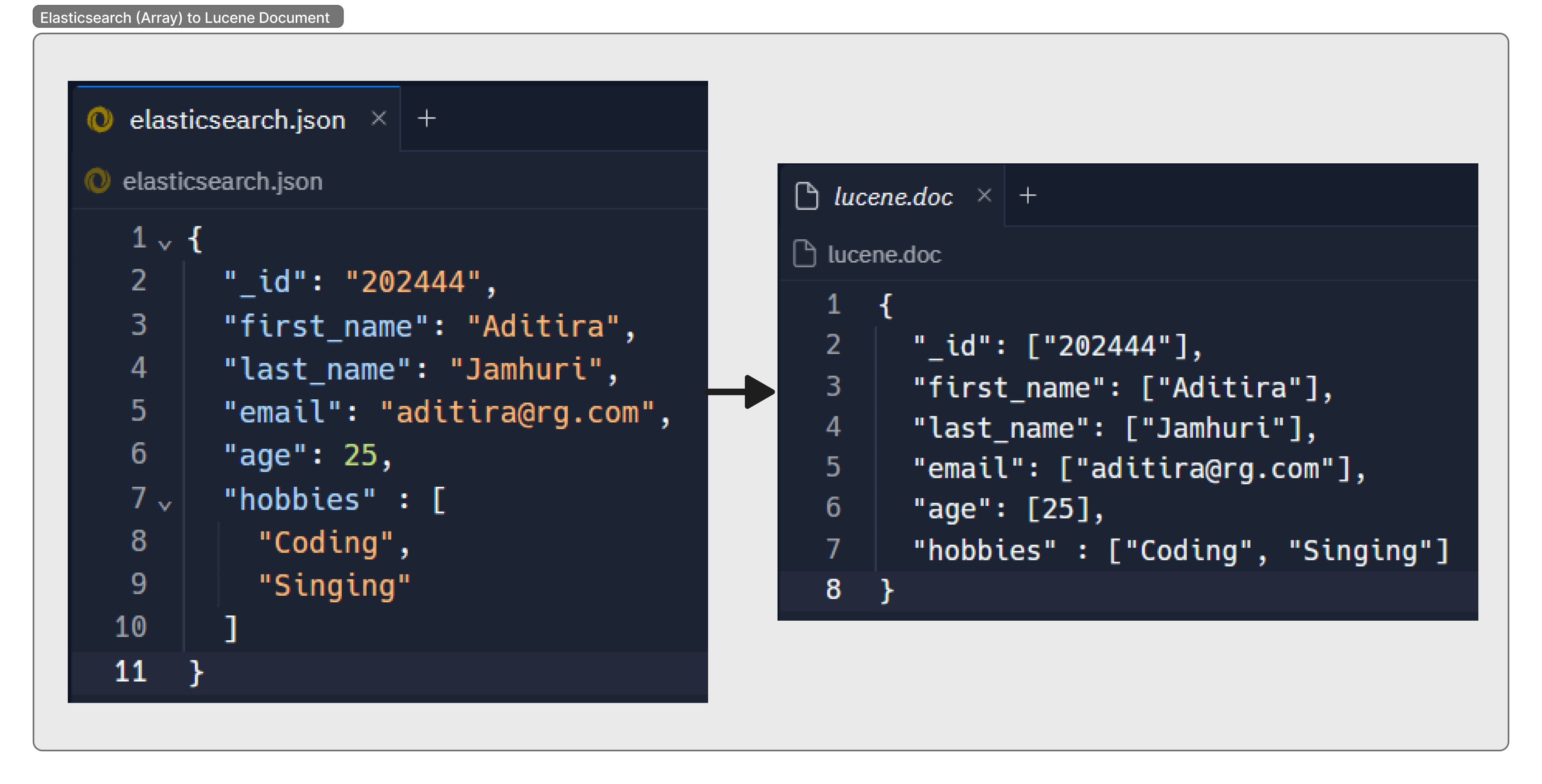
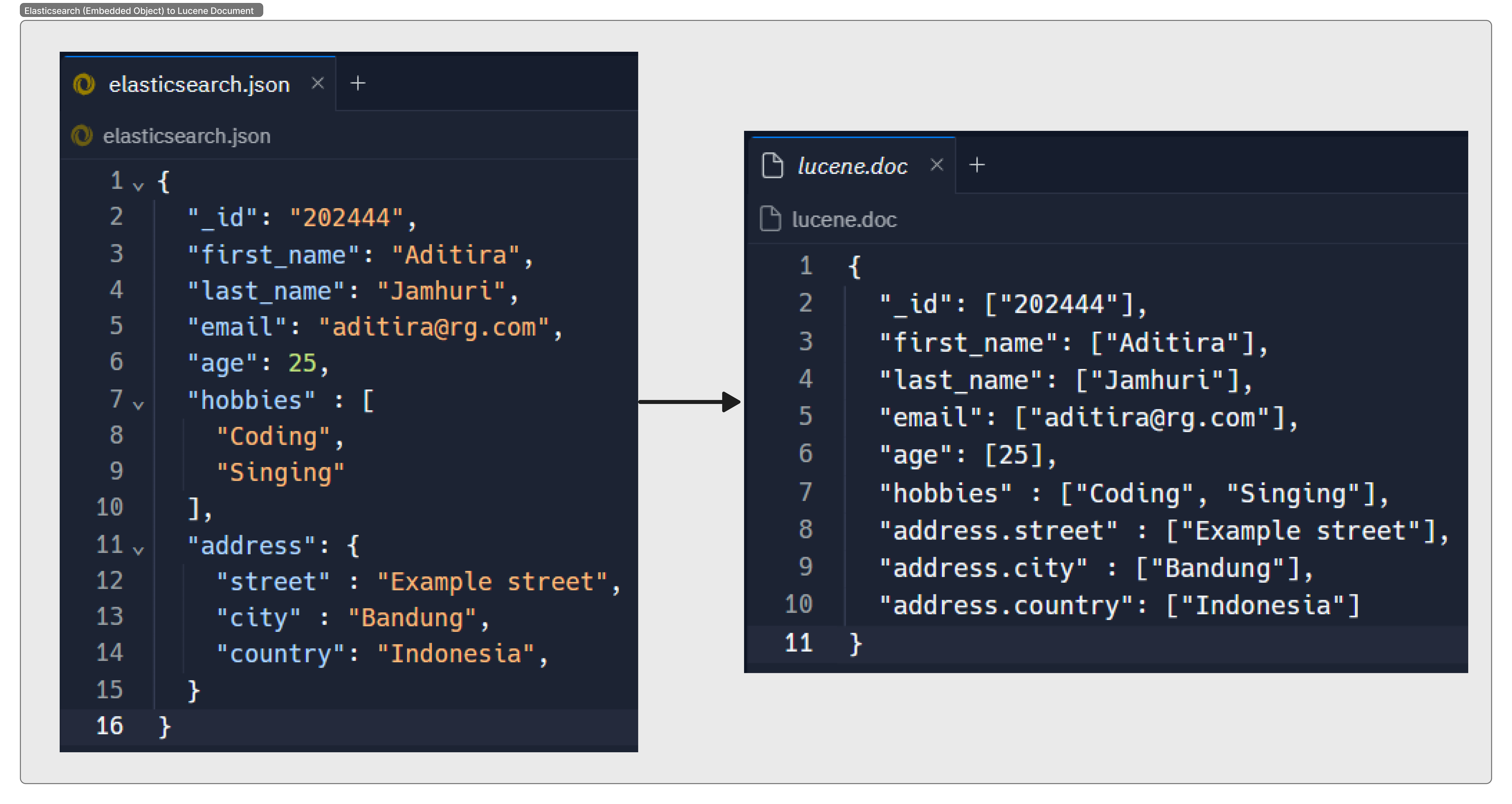
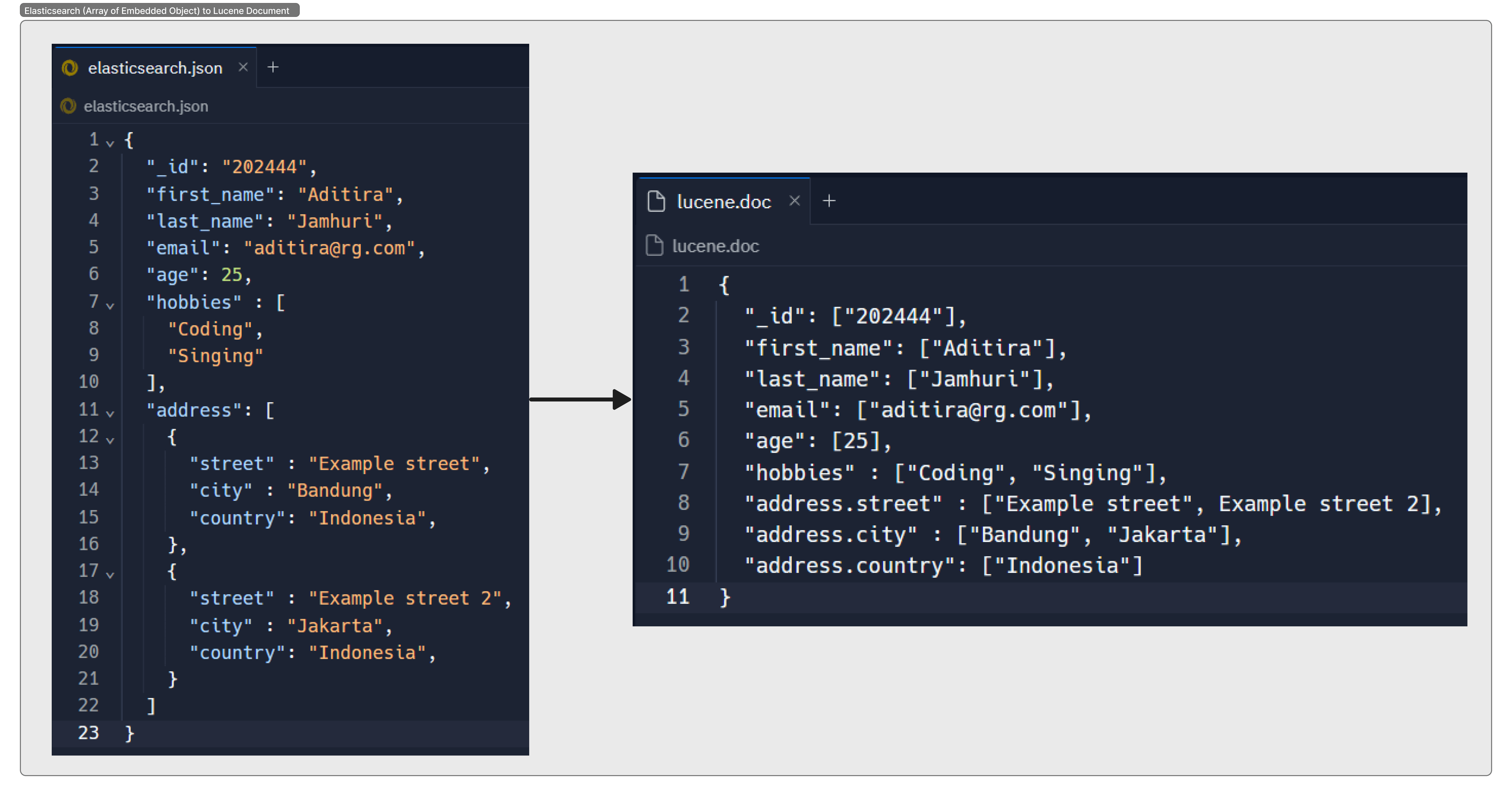
Remember, this is a simplified explanation. The actual process Elasticsearch uses to transform your data into something Lucene can work with involves some complex steps like indexing. But for now, understanding this basic process can help you see how Elasticsearch handles embedded data types.
Back to top