Before we’ve learned about variance which has below formula:
\[
\frac{\sum{(x - \text{mean of } x)^2}}{N}
\]
Given \(X\) is a variable, \(\mu\) is the mean of \(X\), and \(N\) is the number of data points.
Which basically means:
Calculate the difference between each data point from the mean so we know how far each data point is from the mean
Square the difference
Sum all the squared differences
Divide the sum by the number of data points
One point that you need to know about variance it’s basically another name of covariance, but it’s just covariance of a variable with itself. Where does the “with itself” come from? The square of the difference:
\[
(x - \text{mean of } x)^2
\]
How so? This is the formula of covariance: \[
Covariance(x,y) = \frac{\sum_{i=1}^{n}{(x_i - \text{mean of } x)(y_i - \text{mean of } y)}}{N}
\]
So for \(Covariance(x,x)\) it’s the same as saying \(Variace(x)\).
Now let’s expand a bit more on covariance. If we have 5 data points of \(x\) and \(y\): (3, 9), (4, 7), (5, 10), (8, 12), (10, 7), we need to find the mean of \(x\) and \(y\) first which is 6 and 9 respectively. Then we can calculate the covariance of \(x\) and \(y\):
So basically we find the difference between each \(x\) and \(y\) data points with their respective means to know the variation of each data point from the every other data points, then multiply the differences of each data point to know how they relate to each other, then sum all the multiplication results, and divide the sum by the number of data points.
Covariance basic intuition
So there are three basic scenarios for covariance: - Positive covariance: if one variable increases, the other tends to increase as well - Negative covariance: if one variable increases, the other tends to decrease - Zero covariance: if one variable increases, the other doesn’t tend to increase or decrease
We’ll use it later, for now let’s just keep it in mind.
Covariance matrix
For covariance matrix it’s as easy as we’re making a matrix of covariance of each feature with each other feature. So if we have 3 features, we’ll have a 3x3 matrix. For our given example we have 3 features: math, reading, and writing. So it will be like this:
Again for covariance of a variable with itself, it’s called variance. And covariance of \(Covariance(\text{math, reading})\) is the same as \(Covariance(\text{reading, math})\) because intuitively if math and reading are related, then reading and math are related as well.
Quick run through of PCA using basic numpy
We can easily create our own PCA using numpy because it’s mostly just statistics and some linear algebra. Let’s try it
import pandas as pd# Replace 'your_data_file.csv' with the actual path to your CSV filefile_path ='https://storage.googleapis.com/rg-ai-bootcamp/machine-learning/StudentsPerformance.csv'# Load the CSV data into a pandas DataFramedata = pd.read_csv(file_path)numerical_data = data[['math score', 'reading score', 'writing score']]numerical_data
math score
reading score
writing score
0
72
72
74
1
69
90
88
2
90
95
93
3
47
57
44
4
76
78
75
...
...
...
...
995
88
99
95
996
62
55
55
997
59
71
65
998
68
78
77
999
77
86
86
1000 rows × 3 columns
First, we standardize the data by subtracting the mean from each data point (Standardizing data prior to PCA aids in capturing the underlying structure of the data by focusing on the relative variances of variables, making the analysis more meaningful) then we find the covariance matrix:
import numpy as npimport pandas as pd# Your dataX = data[['math score', 'reading score', 'writing score']].to_numpy()# Calculate the meanmean = np.mean(X, axis=0)# Center the datacentered_X = X - mean# Compute the covariance matrixcovariance_matrix = np.cov(centered_X, rowvar=False)# Create a DataFrame with labelscolumn_labels = ['math score', 'reading score', 'writing score']covariance_df = pd.DataFrame(covariance_matrix, columns=column_labels, index=column_labels)# Print the DataFrameprint(covariance_df)
Then we create a transformation matrix from given covariance matrix. The math involved some intermediate steps about eigenvalues and eigenvectors that outside of our scope, but the main intuition is basically we’re trying to find lines we project our data points to that the spread of the projected data points is as big as possible (so we don’t lose much information after the projection). This projection lines dictated by using our covariance matrix.
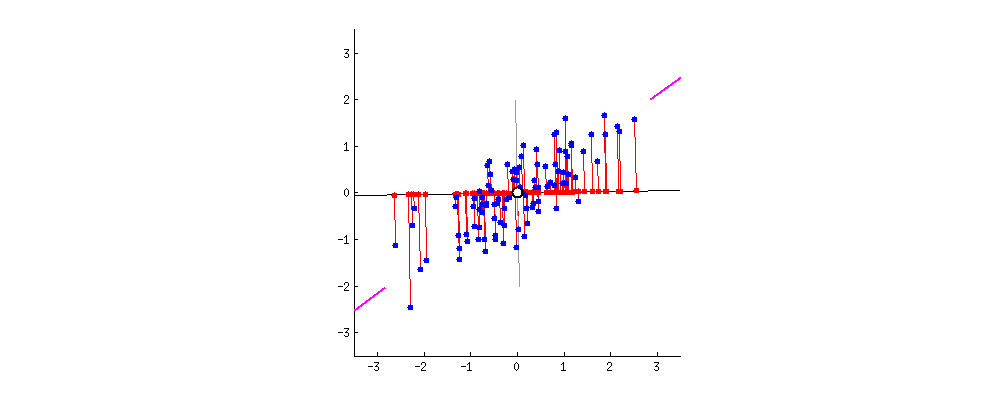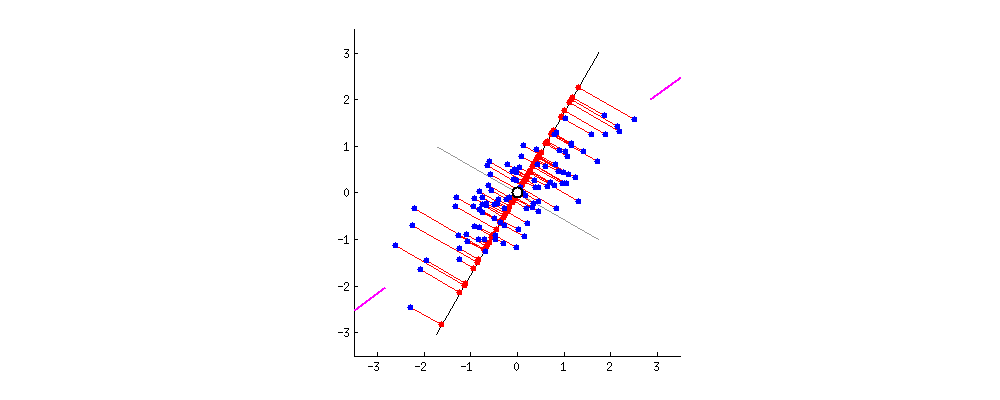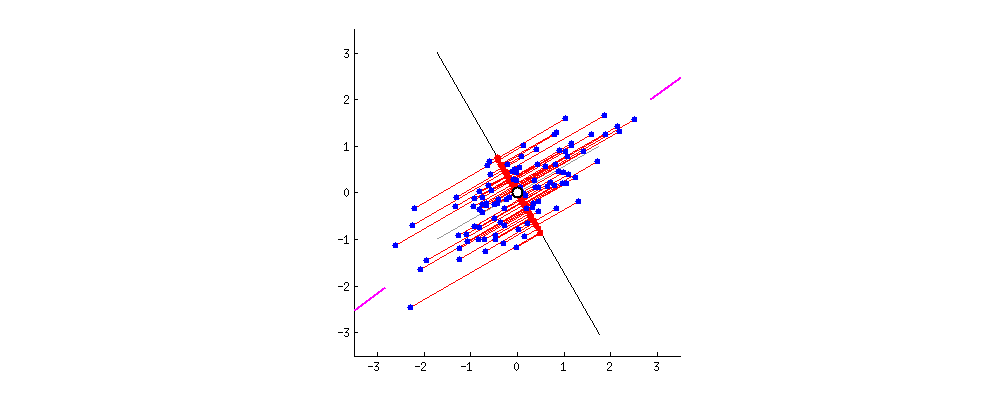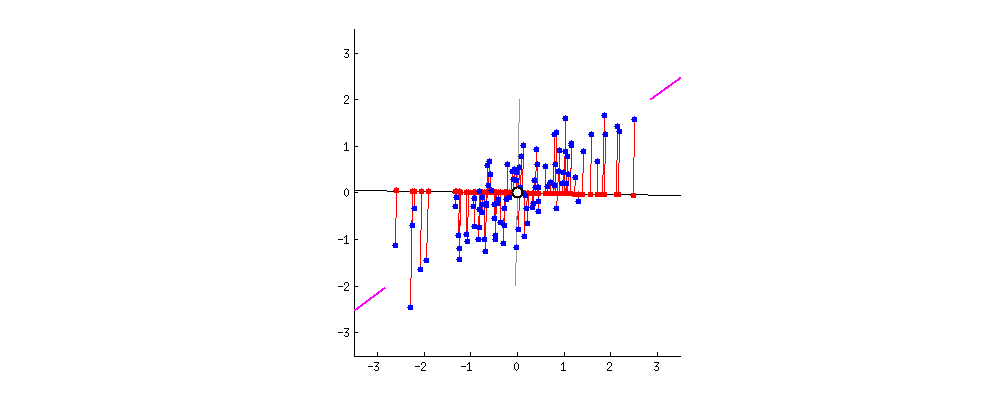
This concept is a little bit hard to understand, but hopefully below illustration can help you to understand it better:
So as you can see above we have two different lines that we can project our data points to from two different angles so that the spread of the projected data points is as big as possible. The process of finding the best line fit can be seen below where the best line fit is when the projection line match with purple lines that you can see on the left and right plot:
It’s kind of finding the linear regression line, but after we found from one angle, we rotate it to find the best line fit from another angle. So basically we’re trying to find the best line fit from all angles.
Now let’s find that best line fit, below \(k\) is the number of principal components that we want to have after the dimensionality reduction. So if we want to reduce our data from 3 dimensions to 2 dimensions, \(k\) will be 2.
k=2# Step 3: Eigen decompositioneigenvalues, eigenvectors = np.linalg.eig(covariance_matrix)# Step 4: Sorting eigenvalues and eigenvectorssorted_indices = np.argsort(eigenvalues)[::-1]eigenvalues = eigenvalues[sorted_indices]eigenvectors = eigenvectors[:, sorted_indices]# Step 5: Selecting the top k eigenvectorstop_k_eigenvectors = eigenvectors[:, :k]top_k_eigenvectors