!pip install gensim
!pip install transformersFeature extraction
In the previous session, we already getting teased at the concept of how our model can know which word is positive, and which is negative. When we’re working on a sentiment classification task with Naive Bayes, there is one step before we can pushed our input to Naive Bayes classifier: Feature extraction.
Feature extraction, like what we might’ve done on previous architecture like CNN, is a way to shape our features so our model can learn. In NLP it’s basically converting our input of sentences to numbers.
Feature extraction can be viewed like word embedding but a lot more simpler, which we’ll learn the difference later in “Word embedding section”
Sheets for the math intution
For our learning we’ll use this sheets to make us learn the math intuition behind what we’ll learn later faster.
https://docs.google.com/spreadsheets/d/1aGhICbKMUvzXjvHKd69sy0-cBdNqfcCMuz27AOLqZh8/edit?usp=sharing
Bag-Of-Words
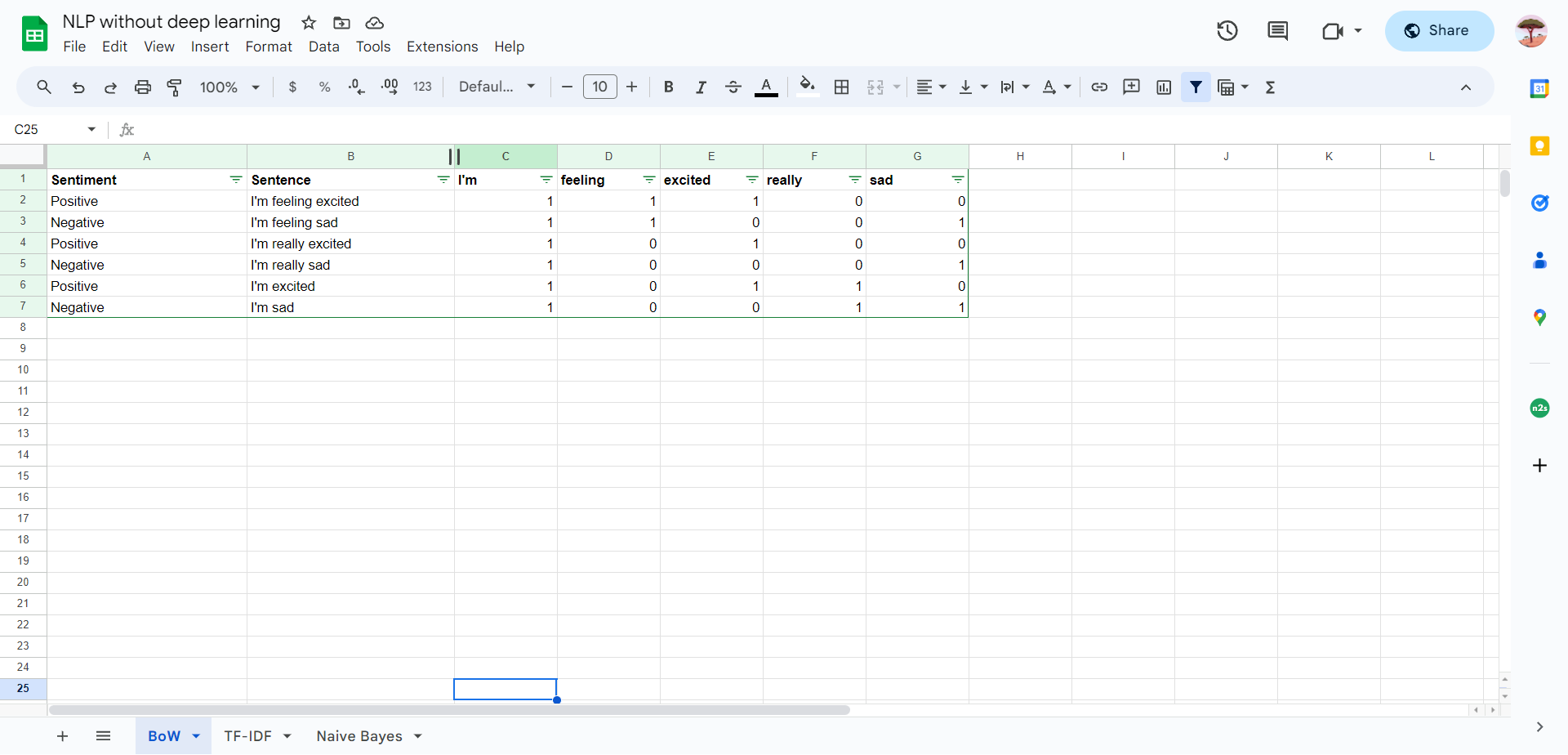
Bag-of-words is a way to convert our tokenized input to matrix of numbers. The concept is really simple: Every word is having their own dimension in the matrix and for every sentence in our tokenized dataset will be converted to that matrix by counting how many times the word is occured on that sentenced.
It’s really simple when we’re seeing the example:

So for every word in our training set, it will have their own dedicated dimensions, and we just count in every sentence on how many each words occured.
In reality, we can just pushed above scores right to Naive Bayes classifier, but we can too learn a simple update from BoW that can help Naive Bayes works better. The “upgraded from BoW” feature extraction method name is TF-IDF.
TF-IDF
Let’s break the name first so we can unmythified this “scary” term.
TF - Term Frequency IDF - Inverse Document Frequency
TF, term frequency, is basically bag-of-words, we count how frequent the term is being use in a single document, basically? Bag-of-words
IDF is where the twist is: If a term is being used so often in the whole dataset, it will lower the score of that words.
I really like your performance on that stage, your words is so mesmerizing!
I don’t like pineapple on pizza, the idea of it even not sounding too exciting
If we’re already removing stopwords, the concept of TF-IDF will help you further finding the “neutral” words that won’t help on your text classification tasks. Just like the word “I” won’t help on our sentiment classification task, but might be not be removed by our stopwords removal process as it’s generally can be use for another task.
TF-IDF helps us let the model know which words should be higher in their scoring towards classification.
The term “inverse” in IDF itself is basically because we’re inversing the quantity: If a word comes too many times, the score would be lower.
TF-IDF Math

For our TF-IDF learning we’ll use previous dataset that we use for our Bag-of-words, and let’s see how TF-IDF will help us reducing importance of the word “I’m” as it’s keep occuring throughout the whole dataset.
IDF calculation
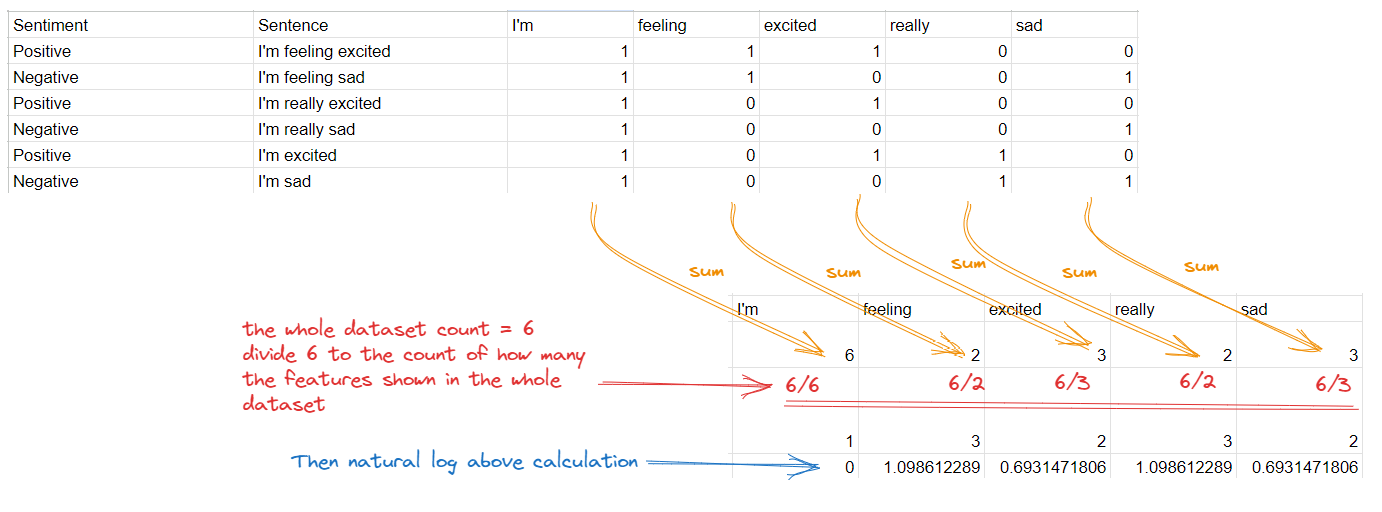
The IDF calculation for a feature is as simple as:
ln(Total number of documents (datasets) / Number of documents with the feature in it)After you do above steps for every single feature, you can see IDF score.
TF-IDF = TF x IDF
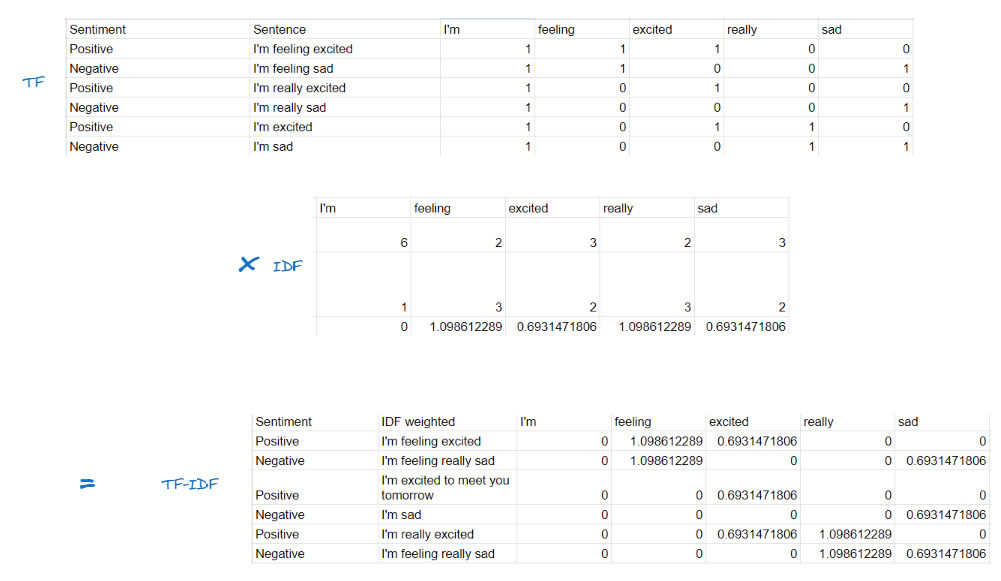
The TF-IDF then can be calculated by simply multiplying the TF for all the inputs to the IDF. Then we’ll see below score
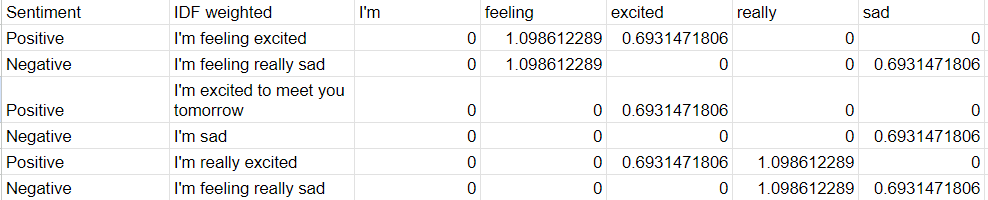
As we can see above that words like “I’m”, because it’s seen basically in every dataset, using this to analyze the sentiment won’t be useful. As for other words they’re now prioritized by their occurence.
Words like “feeling” get higher value than “excited”, simply because our limited dataset has it less than word “excited”. So, for words like this that rarely occured but in reality shouldn’t affect a sentiment, our classification system should move forward to the next step: Using Naive Bayes.
Naive bayes classifier
Naive bayes is one of the most simplest way to do a text classification without neural network. The concept is pretty much like what our intuitions: Finding words that can give hints towards any classification, while shouldn’t give any classification to “neutral words” (words that shouldn’t giving hints towards any classification).
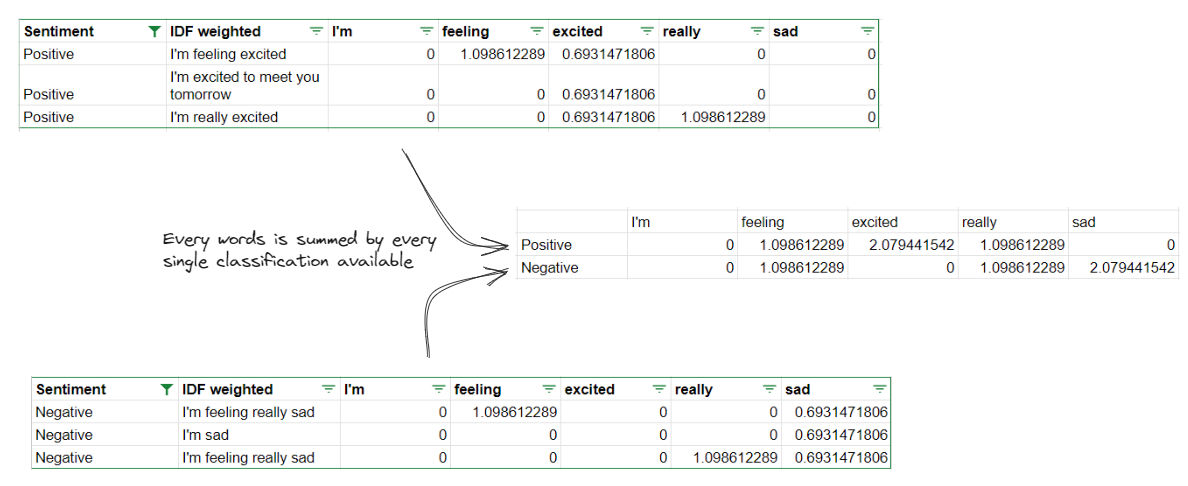
The operation is simple for
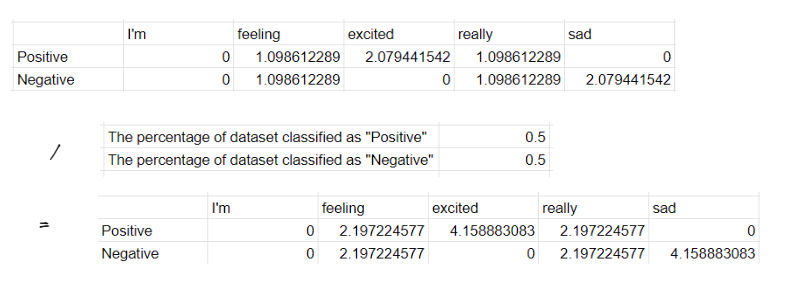
Then we can divide the end score with the percentage of how many is the dataset of every classification is when compared to the total of the entire dataset. As for our current dataset we have 50% data on “positive” sentiment, and 50% data on “negative” sentiment (balanced dataset).

As you can see above using “Naive bayes classifier” we can get every words that are can hint that a sentiment is positive, negative, or neutral.
Positive words would have higher score on the positive sentiment, negative words would have higher score on the negative sentiment, neutral words would have similar (or if there are difference, the difference won’t be significant) score both on positive and negative.
Let’s input our data!
We can now try to input a sentence that our Naive Bayes never seen before:
I’m feeling really sad
The steps is as simple as extract our features to something like below:
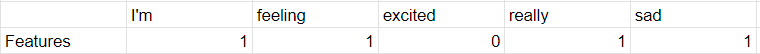
Then after that we multiply with our TF-IDF for each classification, then we’ll get the score for each of word existing in our input.
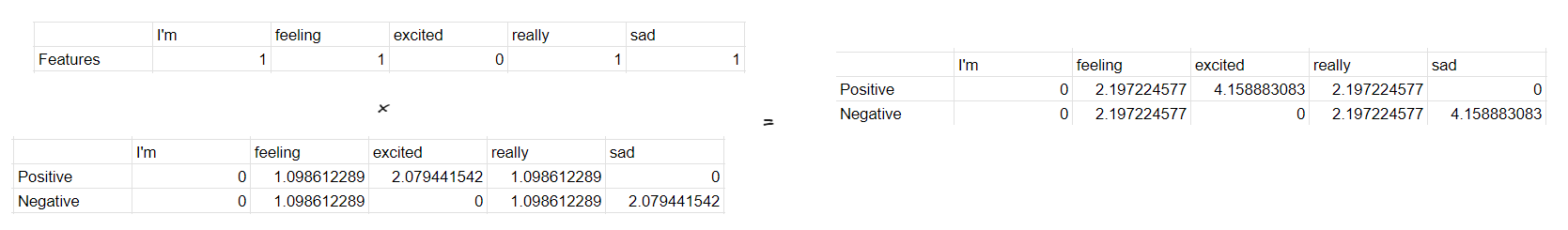
After that to know what classification is our sentence is classified into according to our Naive Bayes we can just sum the per feature scores to a single score for each classsification.
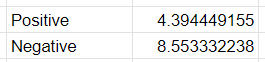
So according to our Naive Bayes, the sentence “I’m feeling really sad”, classified into negative sentiment 💥.
The “naive” part of “naive bayes”
Naive bayes called naive because it’s “naively” consider that every word is independent of each other.
- I am not happy because she just left me
Naive bayes will treat every word as independent, meaning it can’t really “negate” above “happy” word to “not happy”, as it doesn’t really understand between more than a single feature (it can’t create relation between “not” and “happy”, and can’t create conclusion that the word “not” meant to negate the “happy” word).
There are of course other classification method other than “Naive bayes”, even our feature extraction can be improved with more complex method that can somewhat make relation between one word and another without using deep learning.
But in the end, machine learning without deep learning will make us harder to make sure our model understand context, and relations, between words. This is the part where neural networks really excels at when handling NLP: Understanding complex pattern of human words and also acting upon it.
As we can see when learning “Naive Bayes”, without neural network it’s really hard to make a model really understand pattern.
So let’s try to upgrade our understanding and move on to NLP using deep learning!