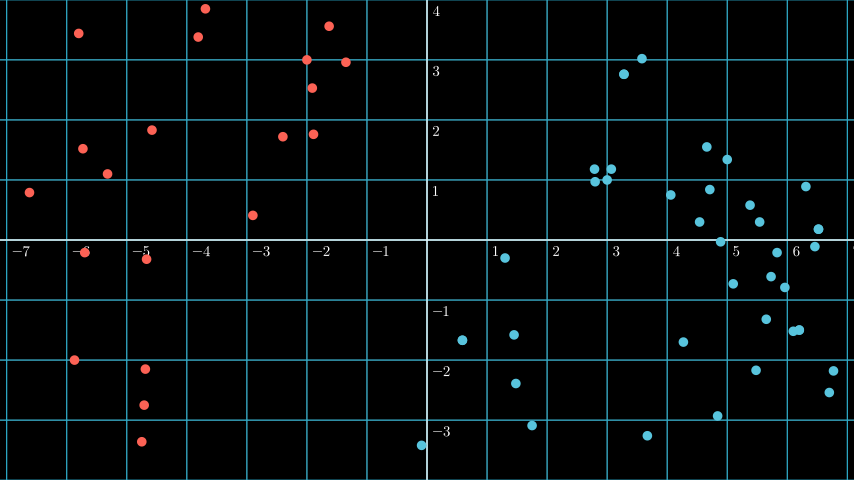
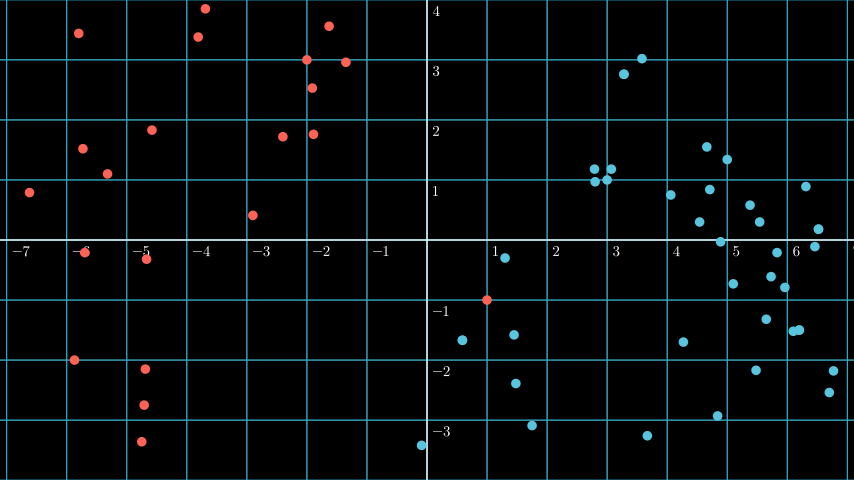
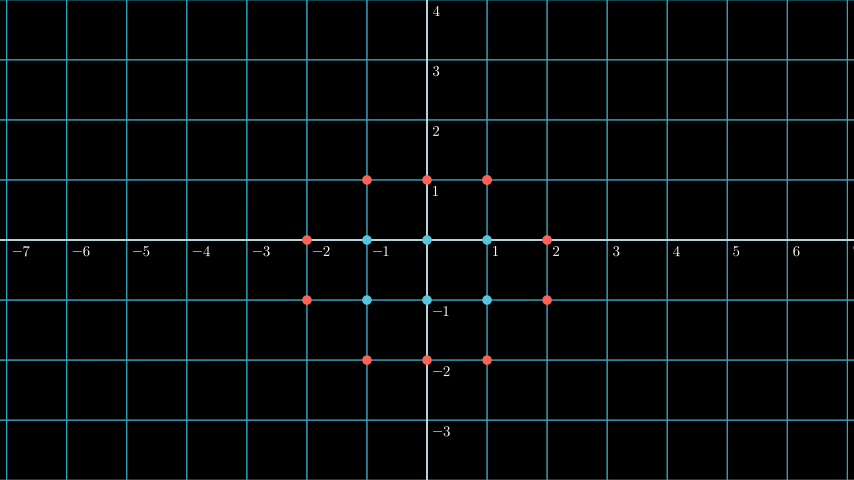
Support Vector Machines (SVMs) are a method in machine learning that can be used for classification . Differ from other classification methods we’ve learned so far, SVMs are based on the idea of finding a hyperplane that best divides a dataset into two classes.
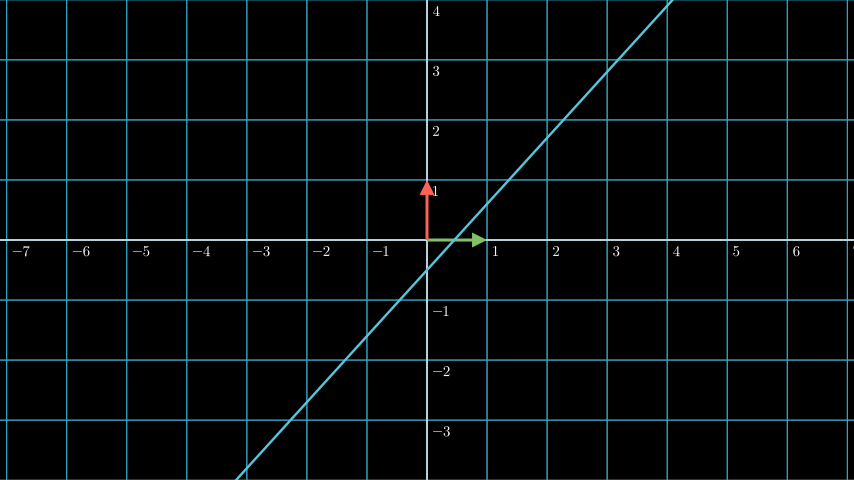
Hyperplane
SVM is highly related with linear algebra, we’re trying “to manipulate” the data to find the best hyperplane. So what is a hyperplane? Hyperplane is a “plane” that has one less dimension than the original data. For example, if we have a 3D dataset, the hyperplane is a 2D plane. If we have a 2D dataset, the hyperplane is a 1D line.
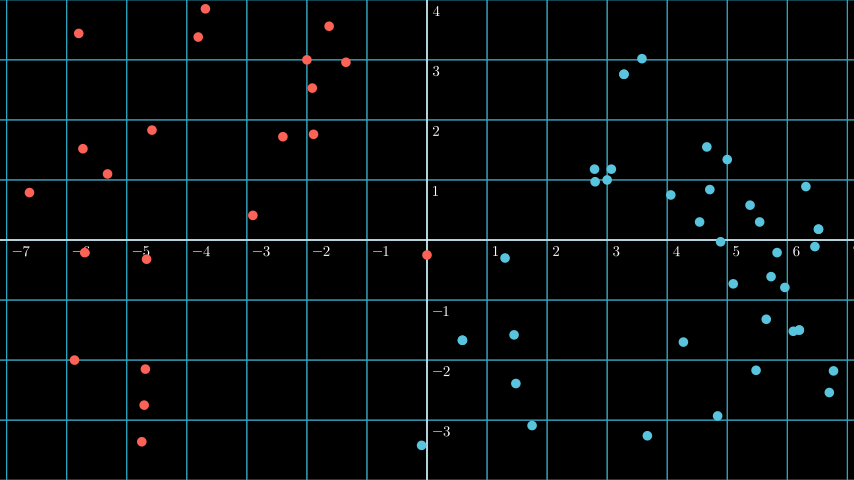
So what’s the relation between a hyperplane and SVM? The hyperplane is the boundary that when a point placed on one side of the hyperplane, it’s classified as one class, and when it’s placed on the other side, it’s classified as the other class.
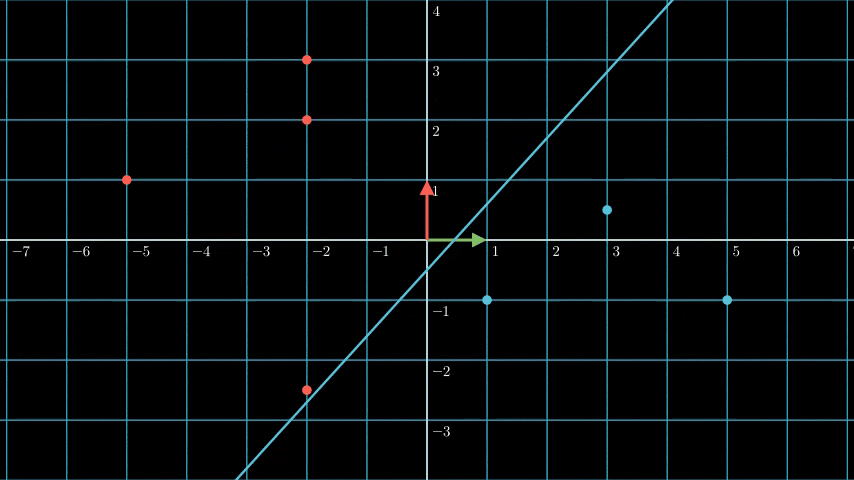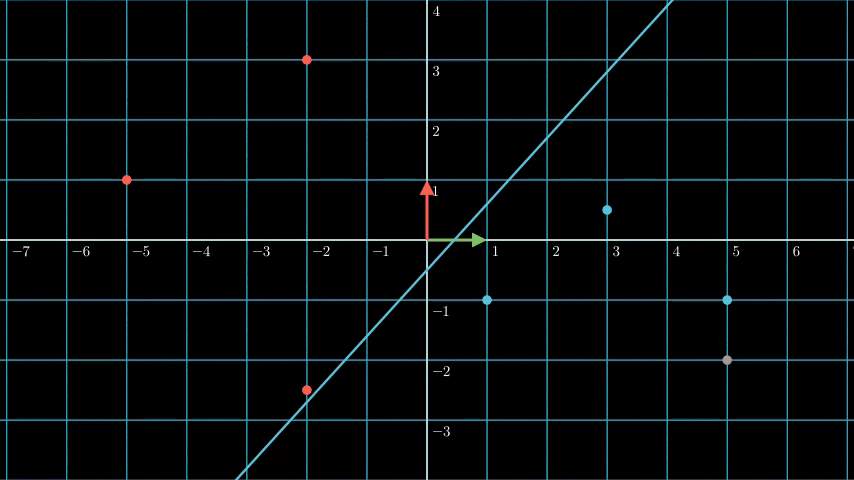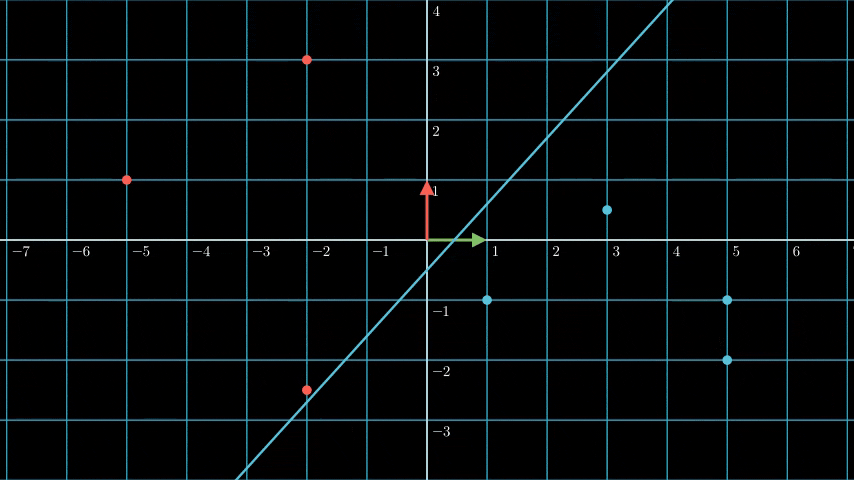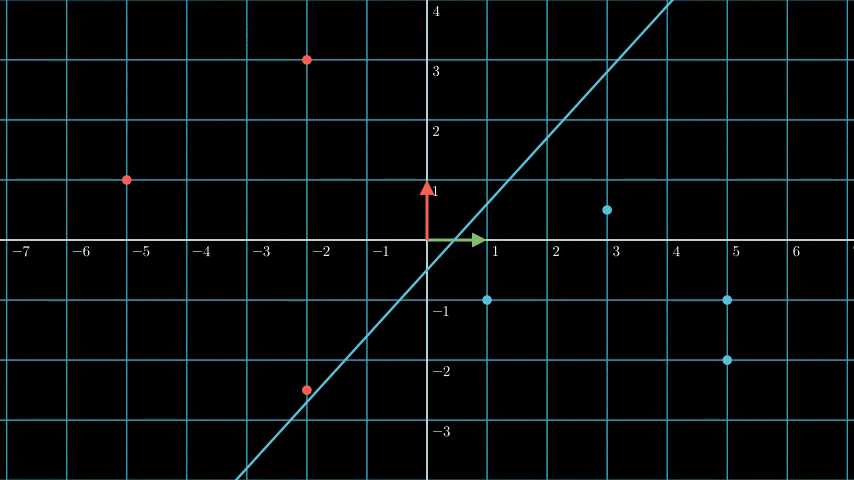
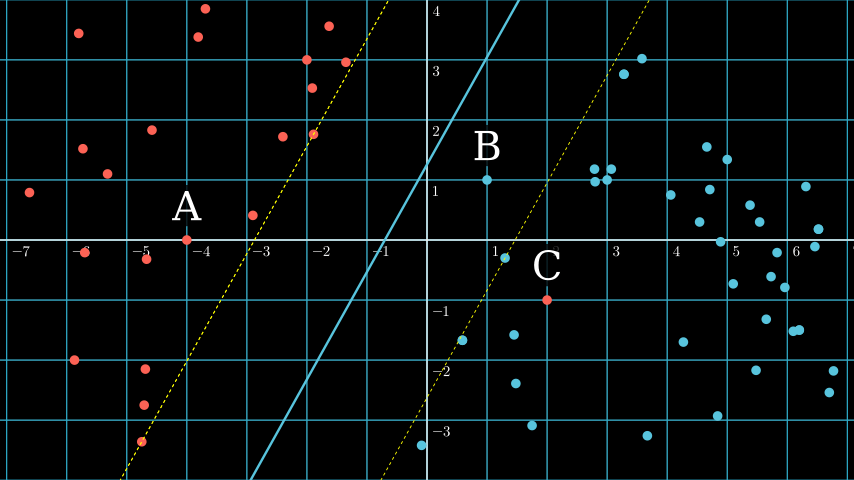
As you can see above if we put the vector at (-2, 2) we can see it’s classified as the red class, and if we put it at (5, -2) the classifcation is blue, it’s because both position is at the different side of the hyperplane.
SVM == The art of finding the most optimal hyperplane
When we’re talking about SVM, we’re talking about how can we find the most optimal hyperplane for our dataset to divide the data into two classes (or more, but we’ll talk about that later). So what is the most optimal hyperplane? The most optimal hyperplane is the one that has the largest margin between the two support vectors.
Margin? Support vector? Understanding how SVM works will be much easier if we understand these two concepts first, let’s quickly go through them.
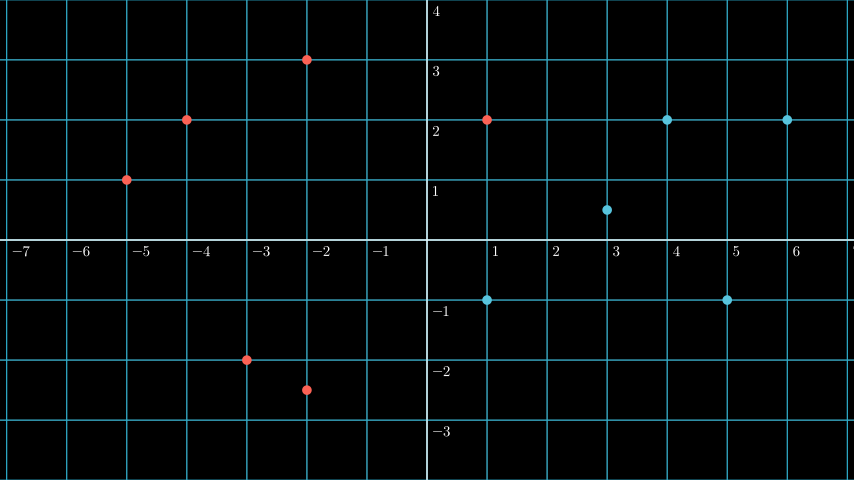
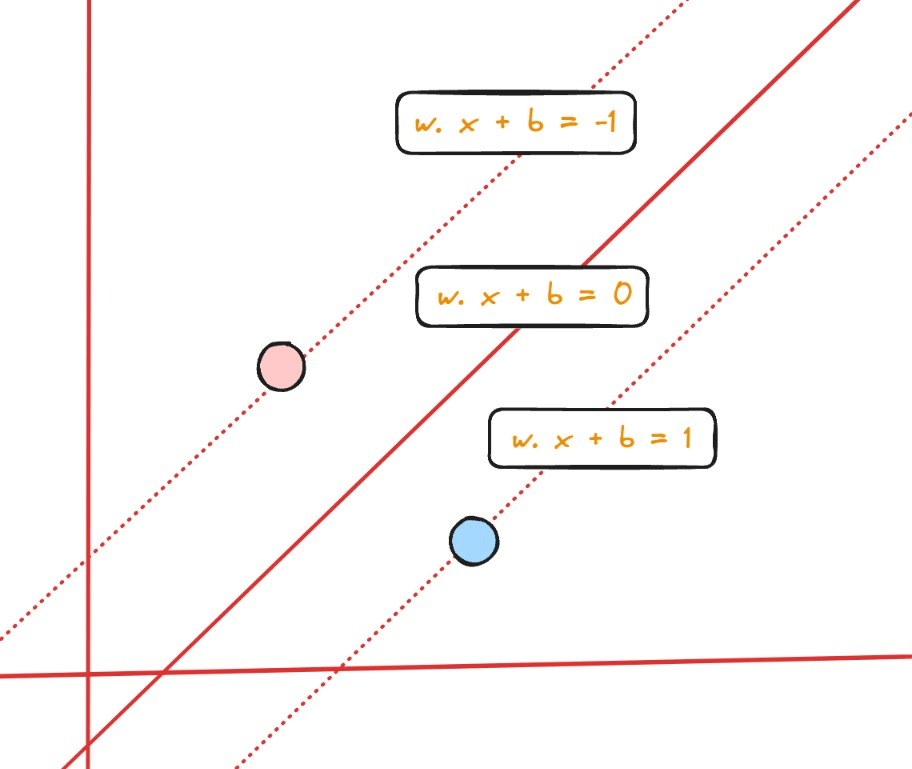
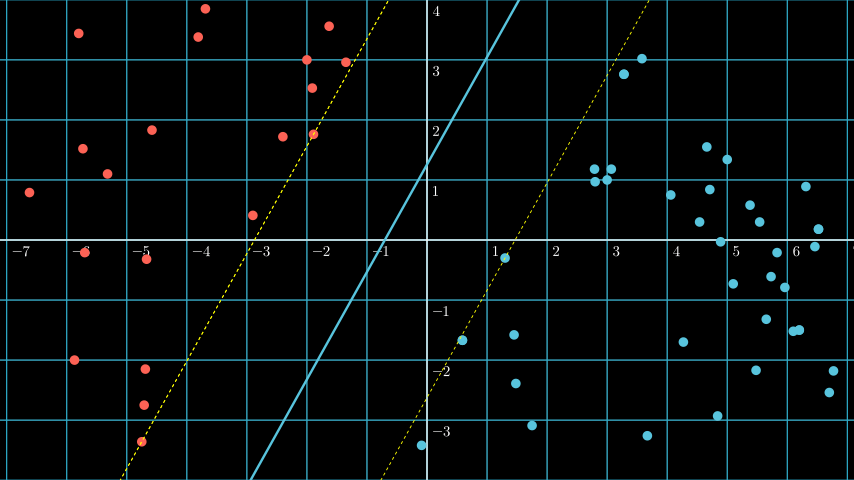
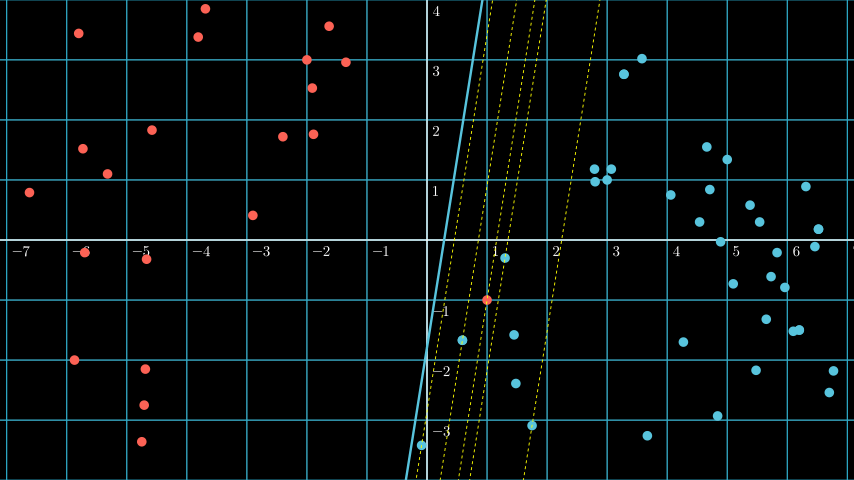
When plotted will make below blue line, a hyperplane for our dataset:
Example for x1
On above plot are two significant concept on how SVM find the most optimal hyperplane, the support vector and the margin.
Remember that the hyperplane on above plot is the blue line.
Support vector are the vectors that are closest to the hyperplane, in above plot we can see dotted lines, the vectors that are on the dotted lines are the support vectors (the dotted line basically means that any vectors that are on that would automatically be classified as the support vector).
Margin is the distance between the support vectors and the hyperplane.
Another term to note is decision boundary, it’s the boundary that separates the two classes, for SVM the hyperplane is the decision boundary.
So how SVM find the most optimal hyperplane? It’s by finding the support vectors from both classes that when we draw a hyperplane between them, the margin is the largest.
Why the largest margin?
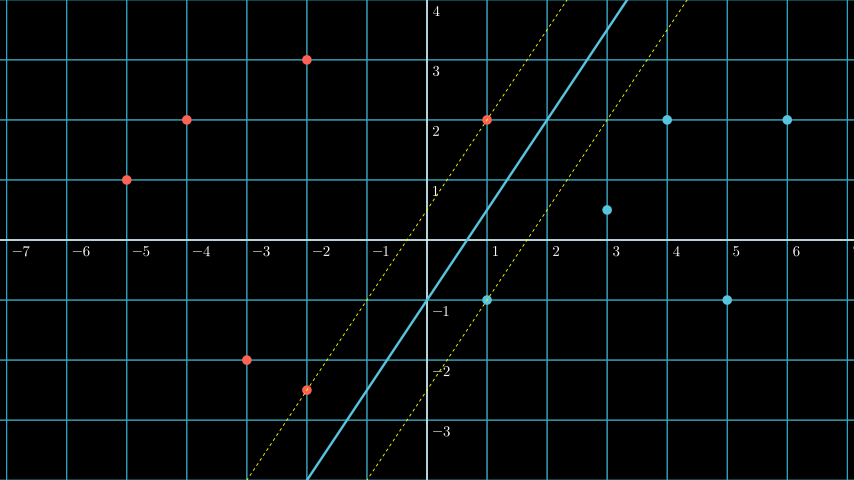
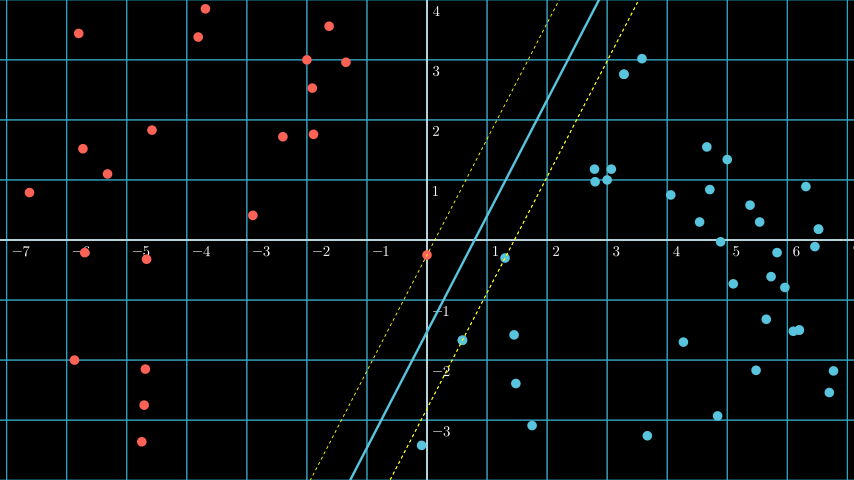
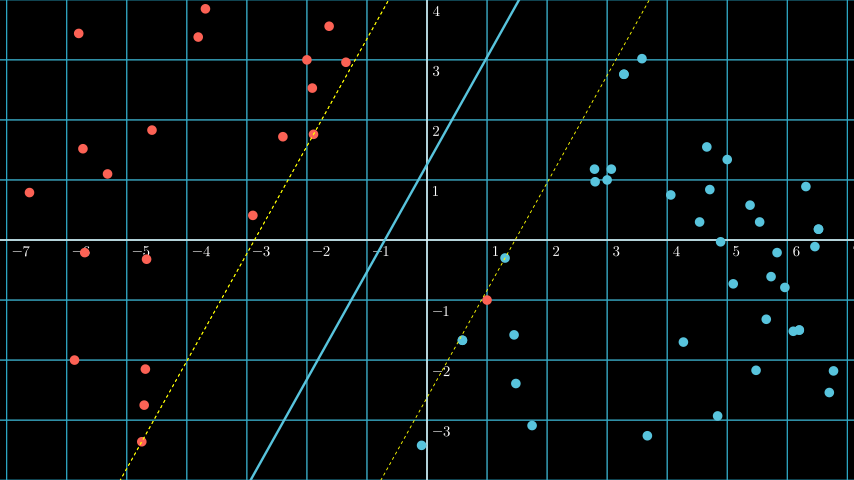
Above we learn that SVM is about drawing hyperplane between support vectors, and the most optimal hyperplane is the one that has the largest margin. But what is the largest margin?
If you see above plot you can see three different hyperplane: Purple, blue, and green.
The problem if we choose the purple line as our hyperplane is that it’s too close with the red support vector, it makes the blue decision boundary slightly “invades” the red region, and it’s bad because it makes the model more prone to misclassification (it’s more likely to misclassify red data as blue).
And the same thing happens if we choose the green line as our hyperplane, it’s too close with the blue support vector, it makes the red decision boundary slightly “invades” the blue region, and it’s bad because it makes the model more prone to misclassification (it’s more likely to misclassify blue data as red).
The ideal hyperplane is the blue line, the ideal margin is the maximum distance between the support vectors of all classes. It’s because the larger the margin, the lower the misclassification rate.
Some math of SVM
Below is the very basic math for the hyperplane and support vector:
\[
\text{Hyperplane}: w \cdot x + b = 0 \\
\text{Support Vector for class 1}: w \cdot x + b = 1 \\
\text{Support Vector for class 0}: w \cdot x + b = -1 \\
\]
Where \(w\) is the weight vector, \(x\) is the input vector, and \(b\) is the bias. To reiterate \(\cdot\) is the dot product.
If above constraint was solved by our SVM model, for inference we can use below formula to classify a vector:
\[
\text{Vector that's classified as class 0}: w \cdot x + b < 0 \\
\text{Vector that's classified as class 1}: w \cdot x + b \geq 0 \\
\]
And if a vector is between \(-1\) and \(1\), it’s on the margin (the area between the two support vectors).
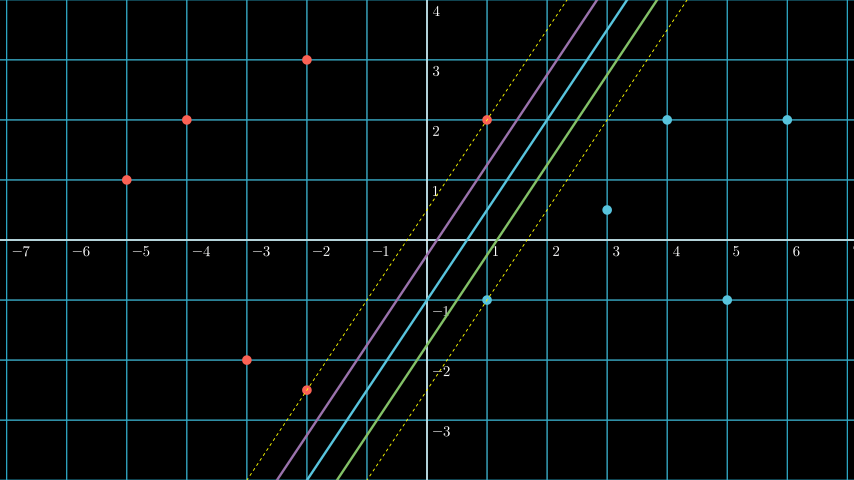
Some explanation for the math
Above is the visual representation of the math, where the center line is the hyperplane, the dotted lines are the lines that goes through the support vectors.
On training we won’t allow for any vectors to be between the two dotted lines (for now we’ll use this assumption, later we’ll learn that it’s a little bit more complicated than that), so we can say that:
If there are any vector between the two dotted lines, it means that the hyperplane is not the most optimal hyperplane, because if there are any vector between the two dotted lines, it means that it would be likely that vector would be the better candidate for the support vector rather than the current support vector. So let’s move the hyperplane a little bit to the vector that’s between the two dotted lines, and we’ll get below:
Let’s train SVM model
Wow, we’ve learned a lot about SVM, before we continue on, let’s take some cool down of adding new knowledge and just train an SVM model.
import numpy as npfrom sklearn import svmX = np.array([[3, 0.5], [5, -1], [1, -1], [6, 2], [4, 2], [-2, -2.5], [-2, 3], [-5, 1], [-3, -2], [-4, 2], [1, 2]])y = np.array([1, 1, 1, 1, 1, -1, -1, -1, -1, -1, -1]) # Blue points (class 1), Red points (class 0) as -1# Create an SVM classifier with a hard margin (What is hard margin?, what is C parameter? We'll learn about it later)clf = svm.SVC(kernel='linear', C=1e5)# Fit the classifier to the dataclf.fit(X, y)# You can now use the trained classifier to make predictions on new data# Get the coefficients (weights) of the hyperplanecoefficients = clf.coef_print("Weights:", coefficients)# Get the bias (intercept) of the hyperplaneintercept_ = clf.intercept_print("Bias:", intercept_)# Get the Support Vectorssupport_vectors = clf.support_vectors_print("Support Vectors:\n", support_vectors)
So if we want to visualize our data in 2D plane for example for our dataset that has two features, we can derive the formula to:
\[
w \cdot x + b = 0 \\
w_1 \times x_1 + w_2 \times x_2 + b = 0 \\
w_2 \times x_2 = -(w_1 \times x_1) - b \\
x_2 = \frac{-(w_1 \times x_1) - b}{w_2} \\
\]
If we want to visualize line that goes through the support vectors, we can derive the formula for vector that’s classified as class 1:
\[
w \cdot x + b = 1 \\
w_1 \times x_1 + w_2 \times x_2 + b = 1 \\
w_2 \times x_2 = 1 - (w_1 \times x_1) - b \\
x_2 = \frac{1 - (w_1 \times x_1) - b}{w_2} \\
\]
And for vectors with class -1:
\[
w \cdot x + b = -1 \\
w_1 \times x_1 + w_2 \times x_2 + b = -1 \\
w_2 \times x_2 = -1 - (w_1 \times x_1) - b \\
x_2 = \frac{-1 - (w_1 \times x_1) - b}{w_2}
\]
import numpy as npimport matplotlib.pyplot as pltfrom ipywidgets import interactdef classify_point(x):""" Classify a point as 'Blue' or 'Red' using the hyperplane from the SVM. Args: x (array-like): The coordinates of the point as a tuple or list. Returns: str: 'Blue' if the point is above the hyperplane, 'Red' otherwise. """ w = np.array([coefficients[0][0], coefficients[0][1]]) # Coefficients of the hyperplane b = intercept_[0] # Intercept of the hyperplane# Hyperplane equation using dot product: np.dot(w, x) + b result = np.dot(w, x) + breturn result# Function to plot the point and the hyperplanedef plot_point(x1, x2): point = np.array([x1, x2]) result = classify_point(point) classification ='Blue'if result >=0else'Red'# Plotting plt.figure(figsize=(8, 6)) plt.axhline(0, color='grey', lw=1) plt.axvline(0, color='grey', lw=1)# Plotting the hyperplane x_vals = np.linspace(-10, 10, 100) y_vals = (-(coefficients[0][0] * x_vals) - intercept_[0]) / coefficients[0][1] plt.plot(x_vals, y_vals, 'green', label='Hyperplane')#Plotting the line that goes through the support vector with class 1 y_vals_1 = (1-(coefficients[0][0] * x_vals) - intercept_[0]) / coefficients[0][1] plt.plot(x_vals, y_vals_1, 'purple', label='Line that goes through support vector with class 1', linestyle='--')#Plotting the line that goes through the support vector with class -1 y_vals_2 = (-1-(coefficients[0][0] * x_vals) - intercept_[0]) / coefficients[0][1] plt.plot(x_vals, y_vals_2, 'purple', label='Line that goes through support vector with class -1', linestyle='--')# Plotting the point plt.scatter(x1, x2, color=classification.lower(), label=f'Point ({x1}, {x2})') plt.xlim(-10, 10) plt.ylim(-10, 10) plt.xlabel('$x_1$') plt.ylabel('$x_2$') plt.title('Point Classification with Hyperplane') plt.legend() plt.show()return classification, result# Interactive functiondef interactive_classification(x1=(-10.0, 10.0), x2=(-10.0, 10.0)): classification, result = plot_point(x1, x2)print(f"The point ({x1}, {x2}) is classified as '{classification}' with result {result:.4f}.")interact(interactive_classification)
Try to place your vector on above interactive plot inside between the two purple lines and check the result. You’ll see that every vector that is plotted inside the margin will be resulted to between -1 and 1.
Let’s remember below properties of SVM
\[
\text{Support Vector for class 1}: w \cdot x + b = 1 \\
\text{Support Vector for class 0}: w \cdot x + b = -1 \\
\]
So for the hard margin SVM we basically have below constraint:
If any vector is placed inside the margin during training, such that
\[
w \cdot x + b \gt 1 \text{ and } w \cdot x + b \lt -1
\]
the SVM model will update the parameters
And remember below properties of SVM also:
\[
\text{Vector that's classified as class 1}: w \cdot x + b \geq 0 \\
\text{Vector that's classified as class 0}: w \cdot x + b < 0 \\
\]
So if a vector that’s classified as class 1 having \(w \cdot x + b \lt 0\) or a vector that’s classified as class 0 having \(w \cdot x + b \geq 0\) the SVM model will update the parameters as there’s a misclassification.
So basically the hyperplane when we use use hard margin SWM won’t be used and will be updated to a new hyperplane that can classify the vector correctly that will fit above constraint (no vector is placed inside the margin).
Which will make it less prone to misclassification for the training data, but it will make it more prone to overfitting.
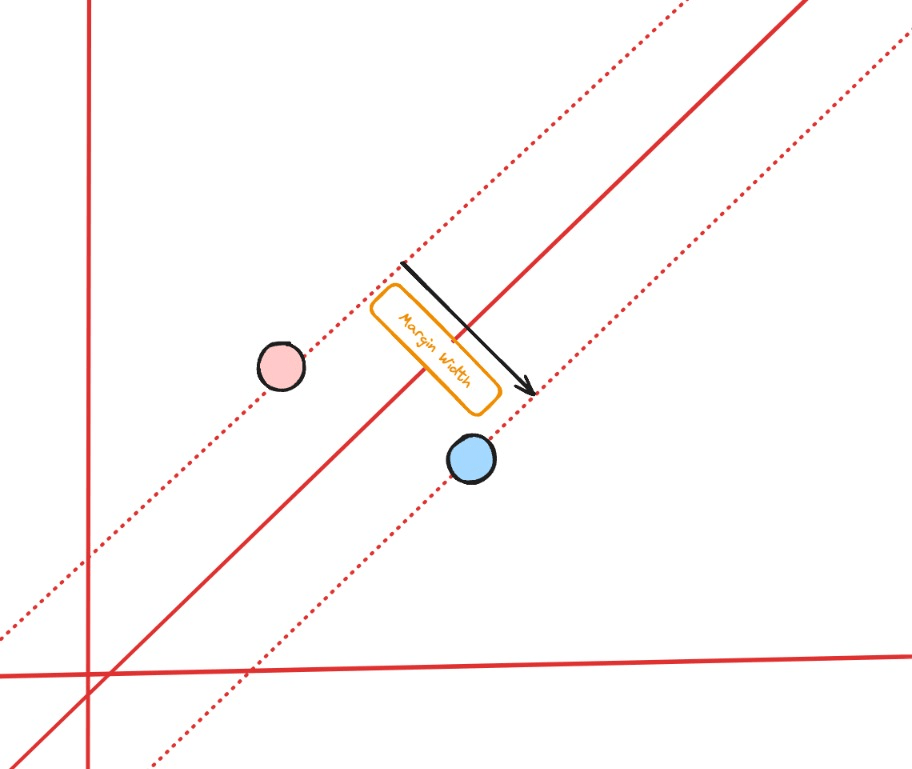
Margin width
Before we continue on learning about hard margin SVM, let’s stop a little bit and learn about margin width.
Margin width is calculated by the distance between the two support vectors, and it’s calculated by below formula:
\[
\text{Width of the margin} = \frac{2}{\|w\|} \\
\]
How to derive the formula can be checked on supplementary material of SVM as it require some additional knowledge of vector math that will be explained there.
Hard margin optimization
So basically when we want to do SVM with hard margin, we want to find the parameters \(w\) and \(b\) that will satisfy below constraint:
\[
\text{Hyperplane}: w \cdot x + b = 0 \\
\text{Support Vector for class 1}: w \cdot x + b = 1 \\
\text{Support Vector for class 0}: w \cdot x + b = -1 \\
\]
And no vector is placed inside the margin, such that \(w \cdot x + b \gt 1\) and \(w \cdot x + b \lt -1\).
If our hyperplane fulfill above constraint, then we need to find the largest margin by looking below formula:
\[
\text{Width of the margin} = \frac{2}{\|w\|} \\
\]
So if we want to find the largest margin, we need to find the smallest \(\|w\|\) (\(w\) vector that has the smallest magnitude) because \(\|w\|\) is in the denominator of the formula.
So on optimizing SVM with hard margin, two things to consider: - Does it fulfill the constraint? - Does it has the smallest \(\|w\|\)?
For optimization of SVM normally we don’t use gradient descent but we use another method called “constrained optimization” (basically like the name suggests, we’re optimizing the model with some constraints), but unfortunately it’s out of the scope of our learning as it’s require a lot of foundation math knowledge such as lagrange multiplier, etc.
Real world has outliers
Let’s be sneaky and add new data that inside the margin of our previous set of data
import numpy as npfrom sklearn import svmX = np.array([ [3.00, 1.00], [3.07, 1.18], [1.48, -2.39], [6.77, -2.18], [5.83, -0.21], [3.67, -3.26], [3.58, 3.02], [-0.09, -3.42], [1.45, -1.58], [2.79, 1.18], [6.10, -1.52], [6.46, -0.11], [6.70, -2.54], [1.30, -0.30], [1.75, -3.09], [2.80, 0.97], [3.28, 2.76], [0.59, -1.67], [6.20, -1.50], [6.52, 0.18], [3.28, 2.76], [0.59, -1.67], [6.20, -1.50], [6.52, 0.18], [4.06, 0.75], [5.10, -0.73], [4.89, -0.03], [6.31, 0.89], [5.54, 0.30], [4.66, 1.55], [5.48, -2.17], [4.27, -1.70], [5.65, -1.32], [4.84, -2.93], [5.38, 0.58], [5.00, 1.34], [4.71, 0.84], [5.96, -0.79], [4.54, 0.30], [5.73, -0.61], [-2.00, 3.00], [-5.80, 3.44], [-3.69, 3.85], [-1.63, 3.56], [-4.67, -0.32], [-4.58, 1.83], [-3.81, 3.38], [-2.90, 0.41], [-4.69, -2.15], [-4.75, -3.36], [-2.40, 1.72], [-1.91, 2.53], [-5.73, 1.52], [-5.70, -0.21], [-5.87, -2.00], [-1.35, 2.96], [-4.71, -2.75], [-6.62, 0.79], [-5.32, 1.10], [-1.89, 1.76]])y = np.array([1,1, 1,1,1,1,1, 1,1,1,1,1, 1,1,1,1,1, 1,1,1,1,1, 1,1,1,1,1, 1,1,1,1,1, 1,1,1,1,1, 1,1,1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,])# Create an SVM classifier with a hard margin (What is hard margin?, what is C parameter? We'll learn about it later)clf = svm.SVC(kernel='linear', C=1e5)# Fit the classifier to the dataclf.fit(X, y)# You can now use the trained classifier to make predictions on new data# Get the coefficients (weights) of the hyperplanecoefficients = clf.coef_print("Weights:", coefficients)# Get the bias (intercept) of the hyperplaneintercept_ = clf.intercept_print("Bias:", intercept_)# Get the Support Vectorssupport_vectors = clf.support_vectors_print("Support Vectors:\n", support_vectors)
Now with above trained SVM, we can see below result:
We can see we have a pretty wide margin for our SVM model, and it’s pretty fair to say if we input of a vector while inferencing say fall into (0, -1) for example, it will be classified as blue and if it falls into (-2, 0) it will be classified as red. The margin pretty wide so the likely that’s accurate is decent.
But, what if on training there is a single outlier like below?
This red dot seems out of place as when we see it, it seems like it should be classified as blue. But this is the nature of real world data, it’s messy and it’s not perfect. Lots of the time we’ll have outliers on our dataset. Let’s see what will happen if we train our SVM model using hard margin with above dataset.
import numpy as npfrom sklearn import svmX = np.array([ [3.00, 1.00], [3.07, 1.18], [1.48, -2.39], [6.77, -2.18], [5.83, -0.21], [3.67, -3.26], [3.58, 3.02], [-0.09, -3.42], [1.45, -1.58], [2.79, 1.18], [6.10, -1.52], [6.46, -0.11], [6.70, -2.54], [1.30, -0.30], [1.75, -3.09], [2.80, 0.97], [3.28, 2.76], [0.59, -1.67], [6.20, -1.50], [6.52, 0.18], [3.28, 2.76], [0.59, -1.67], [6.20, -1.50], [6.52, 0.18], [4.06, 0.75], [5.10, -0.73], [4.89, -0.03], [6.31, 0.89], [5.54, 0.30], [4.66, 1.55], [5.48, -2.17], [4.27, -1.70], [5.65, -1.32], [4.84, -2.93], [5.38, 0.58], [5.00, 1.34], [4.71, 0.84], [5.96, -0.79], [4.54, 0.30], [5.73, -0.61], [-2.00, 3.00], [-5.80, 3.44], [-3.69, 3.85], [-1.63, 3.56], [-4.67, -0.32], [-4.58, 1.83], [-3.81, 3.38], [-2.90, 0.41], [-4.69, -2.15], [-4.75, -3.36], [-2.40, 1.72], [-1.91, 2.53], [-5.73, 1.52], [-5.70, -0.21], [-5.87, -2.00], [-1.35, 2.96], [-4.71, -2.75], [-6.62, 0.79], [-5.32, 1.10], [-1.89, 1.76], [0, -0.25]])y = np.array([1,1, 1,1,1,1,1, 1,1,1,1,1, 1,1,1,1,1, 1,1,1,1,1, 1,1,1,1,1, 1,1,1,1,1, 1,1,1,1,1, 1,1,1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1])# Create an SVM classifier with a hard margin (What is hard margin?, what is C parameter? We'll learn about it later)clf = svm.SVC(kernel='linear', C=1e5)# Fit the classifier to the dataclf.fit(X, y)# You can now use the trained classifier to make predictions on new data# Get the coefficients (weights) of the hyperplanecoefficients = clf.coef_print("Weights:", coefficients)# Get the bias (intercept) of the hyperplaneintercept_ = clf.intercept_print("Bias:", intercept_)# Get the Support Vectorssupport_vectors = clf.support_vectors_print("Support Vectors:\n", support_vectors)
If we’re forced to use hard margin SVM, we’ll have above result. Let’s iterate first that by default when we’re training SVM using scikit learn, it will using soft margin SVM, on above training we use a really high C value (which we’ll learn in a bit) to force it to use hard margin SVM, but by the nature of scikit we still can found the result even with hard margin SVM (in reality this shouldn’t be solvable using hard margin SVM).
But as we can see above this outlier make the hyperplane gone very near to the blue region, making the red region very big and can make lots of inputs misclassified as red rather than if we insist of using below hyperplane.
If we can ignore the outlier, we can see that the hyperplane is much more balanced and the margin is much wider. So how can we make sure that our SVM model can ignore the outlier?
Soft margin
Soft margin SVM is a method to allow some misclassification on our SVM model which means that the resulting hyperplane sometimes can ignore having some vectors inside the margin or any vectors that are misclassified.
So rather than previously that hard margin SVM is focused only on maximing margin width while still considering given constraint, soft margin SVM is focused on maximizing margin width while letting some misclassification to happen in training where this misclassification is controlled by a parameter called slack variable that we already often see before denoted as C.
How much do we care about bringing high margin width vs how much do we care about making sure not much misclassification can be goes through the model? To understand better about slack variable let’s understand about hinge loss first.
Hinge loss
Hinge loss is basically a loss function that said: “Given current hyperplane, how bad this hyperplane is at classifying the data?”. So if we have a hyperplane that can classify all the data correctly, the hinge loss will be 0 (this will be the case on a data with no outlier). But if we have a hyperplane that can’t classify all the data correctly (some data might be misclassified), the hinge loss will be greater than 0.
So let’s check the below set of data and given hyperplane:
Basically if the vector is correctly classified but inside the margin, the hinge loss will be greater than 0 but always less than 1 (if the result is greater than 1, it means the vector is misclassified which we’ll learn next).
This means that if there is a data that’s correctly classified but inside the margin, there is small penalty that we want to inform the SVM model for the current iteration of the hyperplane.
So as you can see if any of the vector is misclassified for the current iteration of the hyperplane, the hinge loss will be greater than 1. It means that there is a huge penalty that we want to inform the SVM model that saying “Hi, you might want to look at this vector because this vector is completely misclassified”.
Above is the formula for the loss function, compiled between the hinge loss and the loss function for the margin width. Basically if we want to allow as much as misclassification as possible, we can set the \(C\) to 0, which means the model won’t care about the margin width at all, while if we make it as big as possible, the hinge loss will be really small that it won’t have any effect on the loss function, which means the model will care about the margin width as much as possible, granting the similar result as hard margin SVM (which is why we can still get the result on hard margin SVM using scikit learn, because it’s still basically soft margin SVM with a really high \(C\) value).
\(C\) value commonly called as the regularization parameter or slack variable, and it’s a hyperparameter that we can tune to get the best result for our SVM model.
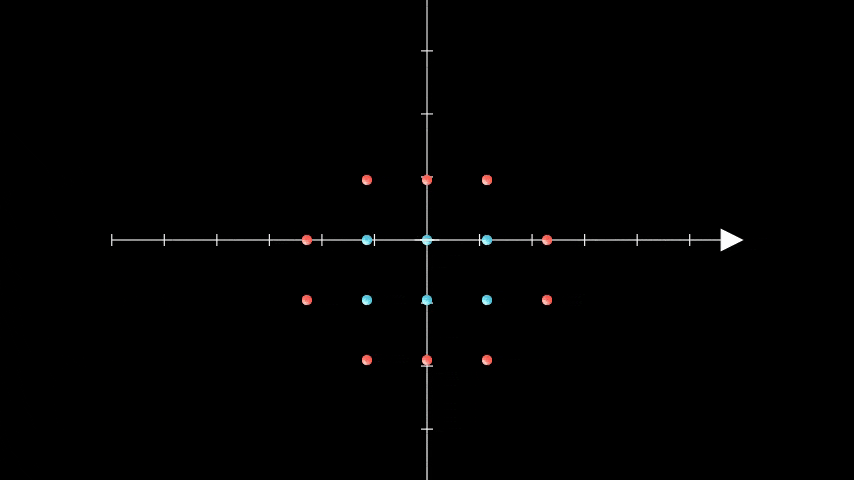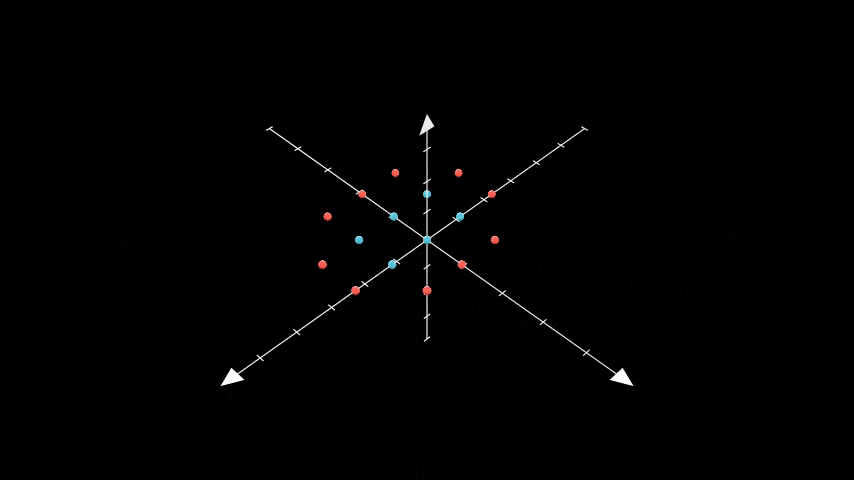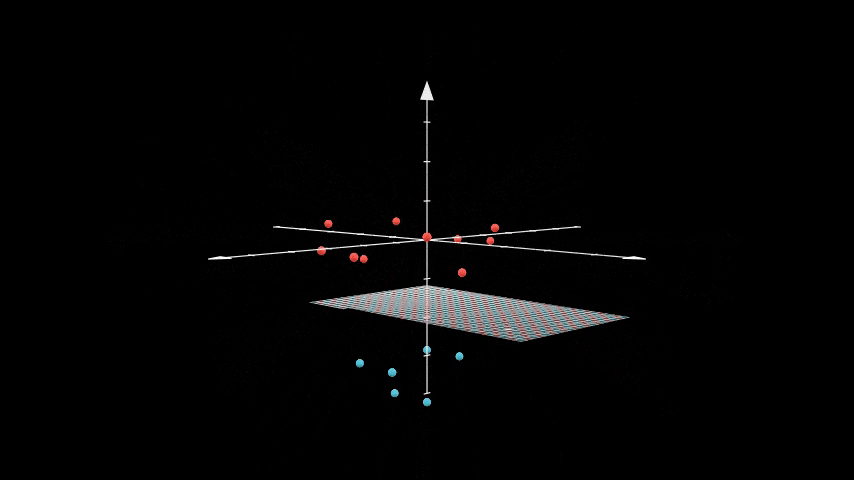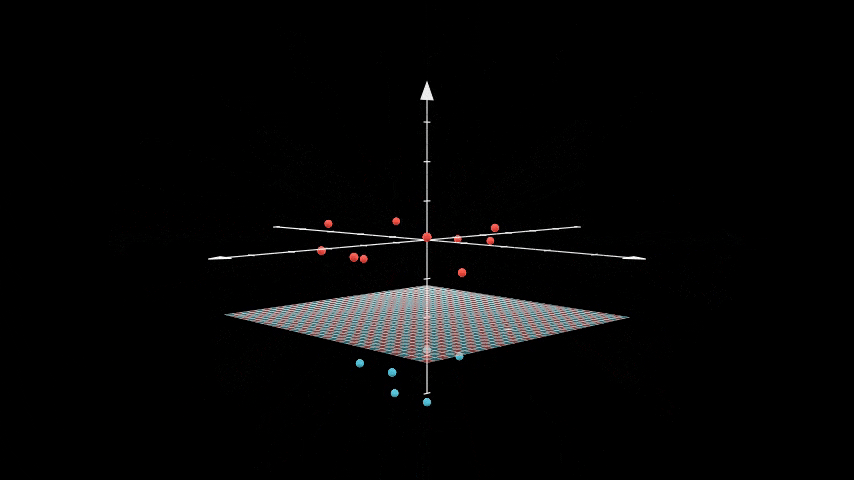
Linearly Separable Data
If we get back to this plot:
This plot is based on a dataset that is linearly separable, which means we can draw a simple hyperplane (for this case a line) to separate the data into two classes. But what if the data is not linearly separable? What if we have a dataset like this:
As you can see from above data we can’t draw a hyperplane to separate the data into two classes. Let’s reiterate about hyperplane is that it’s a plane that has one less dimension than the original data. So for above data, the hyperplane is a line, and we can’t just draw a line to separate the data into two classes.
This formula will generate z value for each vector in the matrix by using the x and y value of the vector.
So we can see below how, by transforming existing data into a new dimension, we can draw a hyperplane to separate the data into two classes where above example we now have 3 dimensional data, and the hyperplane is a 2D plane.
Note: For above example, we used polynomial regression to get above formula where we target all the red dots to be on 0 axis while blue dots to be on -3 axis
Implicitly adding new dimension - Kernel Trick
As you can see above, we can transform a data to higher dimension and it can provide a new “perspective” on that data. What if three dimensions is not enough? What if we need more dimensions? What if we need 100 dimensions? 1000 dimensions? 10000 dimensions? It’s not practical to do that, right?
Understanding the optimization method on SVM
One of the most used optimization method on SVM that can help on how to find the most optimal hyperplane is called dual problem, which can be seen below:
\(\alpha_i\) are the Lagrange multipliers (dual variables) associated with each training sample $ _i $.
\(y_i\) is the class label of training sample $ _i $ (-1 or 1).
\(K(\mathbf{x}_i, \mathbf{x}_j)\) is the kernel function that computes the dot product between the feature vectors $ _i $ and $ _j $ in the transformed feature space.
Okay, so maybe we’ve got to go through lots of math to understand what’s going on (we need to delve in on constrained optimization which out of scope of our learning), but for now let’s focus on the \(K(\mathbf{x}_i, \mathbf{x}_j)\) part. Why? Because \(\alpha_i\) and \(C\) are data that is part of the model output after training, but \(K(\mathbf{x}_i, \mathbf{x}_j)\) is the kernel function that we are interested because this value is derived from the input data, and as you can see, the kernel function is outputting the dot product between two vectors in a higher dimension.
Above optimization method is only using the dot product between all pairs of input data to find the most optimal hyperplane. So if we can find a way to calculate the dot product between two vectors in a higher dimension without actually transforming the data into that dimension we can save lots of computation power and make our model more efficient and faster to train. And that’s what above kernel function means: A “trick” to fasten the computation by implicitly adding new dimension, mimicking as if we’re calculating the dot product in a higher dimension without actually transforming the data into that dimension.
Why can we only use the dot product to find the most optimal hyperplane?
Unfortunately, the concept of “why” is beyond the scope of our learning, because there are lots of foundational math, especially in the field of quadratic programming, that we need to learn first before we can understand why we only need the dot product.