Data interpretation is not just a statistical process; it’s a strategic tool that helps businesses make informed decisions. It’s also a fundamental step in preparing for the exciting world of machine learning.
Why do businesses like ‘SodaPop’, a soft drink company, need to delve into data interpretation? 🤔 The answer lies in the need to answer crucial business questions, such as:
“Which of our products do customers prefer?” or
“What are the main factors influencing a customer’s decision to choose between ‘SodaPop Classic’ and ‘SodaPop Zero’?”
In the case of ‘SodaPop’, they face a challenge. They have gathered customer survey data but are unsure how to interpret it to gain valuable insights about customer preferences. This is where data interpretation comes in.
Data Interpretation: A Critical Precursor to Machine Learning
For instance, some customers might prefer “SodaPop Classic” due to its taste, while others might select “SodaPop Zero” for its lower calorie content. The interpretation process helps SodaPop uncover these consumer preferences and behaviors, setting the stage for predictive modeling and algorithmic decision-making in machine learning.
Data interpretation comes in two general flavors, both of which are intimately linked to machine learning:
Qualitative, emphasizing descriptions and interpretations.
Quantitative, focusing on numbers and statistics.
Before embarking on the data interpretation journey, SodaPop needs to decide on the data measurement scale. They might categorize data by product (a nominal scale), sort it by customer satisfaction level (an ordinal scale), analyze the distribution of customer ages (an interval scale) or analyze the ratio of customers who choose “SodaPop Classic” compared to “SodaPop Zero” (a ratio scale).
With the measurement scale selected, SodaPop can now choose the interpretation process that best suits their data needs. They might perform a trend analysis to understand how customer preferences change over time or a correlation analysis to see the relationship between variables like age and product preferences.
Data Interpretation in Practice: The SodaPop Example
Imagine we have survey data from the SodaPop company. This data includes columns for ‘Product’ (the product the customer chose), ‘Age’ (the customer’s age), ‘Satisfaction’ (the level of customer satisfaction), and ‘CalorieConcern’ (whether the customer is conscious about calorie intake).
Note: Do note that this generated data serves as an example and might not fully reflect the actual situation a soft drink company may encounter.
Applying Data Interpretation
Nominal Data
Nominal data is a type of categorical data where the variables have two or more categories without having any kind of order or priority. The “name” is the meaning of the word nominal.
For example, in the context of the SodaPop company, the ‘Product’ variable is a nominal data type because it classifies data into distinct categories:
SodaPop Classic
SodaPop Zero
These categories don’t have a specific order or hierarchy.
Nominal data is considered Qualitative as it expresses a characteristic or quality that can be counted but not measured on a standard scale.
Ordinal Data
Ordinal data, on the other hand, is a type of categorical data with a set order or scale to it. It’s still qualitative, but unlike nominal data, the order of the values is important.
For example, in the SodaPop context, ‘Satisfaction’ is an ordinal data type. The satisfaction levels range from ‘Very Unsatisfied’ to ‘Very Satisfied’, and the order of these categories carries significant meaning:
Very Unsatisfied
Unsatisfied
Neutral
Satisfied
Very Satisfied
Ordinal data is also considered Qualitative, as it represents discrete categories that have a ranked order.
Interval Data
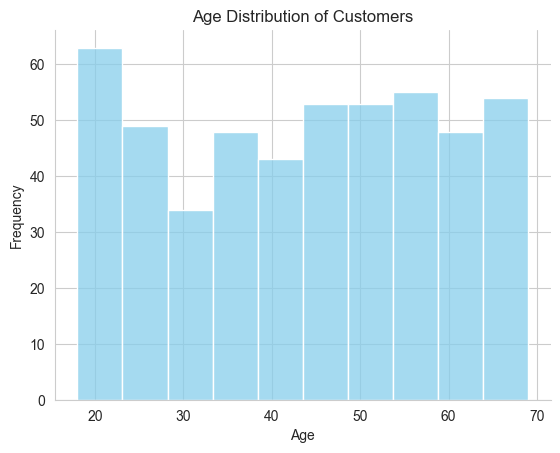
We use interval data to understand the distribution of a continuous variable, like ‘Age’ of customers. We can illustrate this distribution using a histogram. The height of each bar in the histogram indicates the number of customers in a specific age range. This visual representation allows companies to identify the most common age groups among their customers, which can be useful for tailoring marketing strategies.
Here is the simplified visualization:
# @title #### Interval Chartsimport seaborn as snsimport matplotlib.pyplot as pltsns.set_style("whitegrid")ax = sns.histplot(df['Age'].dropna(), bins=10, color='skyblue')ax.set_title('Age Distribution of Customers')ax.set_xlabel('Age')ax.set_ylabel('Frequency')sns.despine(ax=ax, top=True, right=True)plt.show()
Interval data is Quantitative as it represents measurements and hence numerical values. This type of data can be measured on a scale and has a clear numerical value.
Ratio Data
Ratio data helps us understand the relationship between two quantities. In our case, we calculate the ratio of customers choosing “SodaPop Classic” versus “SodaPop Zero”. This gives us insight into customer preferences.
# @title #### Ratioclassic_count = df[df['Product'] =='SodaPop Classic'].shape[0]zero_count = df[df['Product'] =='SodaPop Zero'].shape[0]ratio = classic_count / zero_countprint(f'Number of customers who chose SodaPop Classic: {classic_count}')print(f'Number of customers who chose SodaPop Zero: {zero_count}')# print calculateprint(f'The ratio of customers who chose SodaPop Classic to SodaPop Zero is {ratio:.2f}')
Number of customers who chose SodaPop Classic: 255
Number of customers who chose SodaPop Zero: 245
The ratio of customers who chose SodaPop Classic to SodaPop Zero is 1.04
Ratio data is also a Quantitative data type. Like interval data, ratio data can also be ordered, added or subtracted, but in addition, it provides a clear definition of zero, and it allows for multiplication and division.
The Importance of Data Interpretation
Data interpretation is key for informed decision-making, trend spotting, cost efficiency, and gaining clear insights. This process is fundamental not only for businesses like “SodaPop”, but also for machine learning applications.
Informed Decision Making: Interpreting data allows “SodaPop” to make fact-based decisions. For example, if “SodaPop Classic” is preferred by customers, they might increase production. This mirrors supervised machine learning, where models make predictions based on training data patterns.
Identifying Trends: Data interpretation helps “SodaPop” spot consumer trends, like a growing demand for low-calorie drinks, leading to new product ideas. This resembles the predictive nature of machine learning, where models forecast future trends based on past data.
Cost Efficiency: Correct data interpretation can result in cost savings. If the production costs of “SodaPop Classic” are higher than its demand, cutting production might be beneficial. This is similar to optimization in machine learning, where algorithms minimize a cost function to find the best solution.
Clear Insights: Through data analysis, “SodaPop” can gain valuable insights about their business, like identifying sales dips during a particular month, prompting proactive measures. This echoes the exploratory phase in machine learning, which helps select the right model.
In short, data interpretation is vital for companies like “SodaPop”. It supports better decision-making, improves business performance, and provides a foundation for advanced machine learning applications, where data interpretation is used for predictive modeling and algorithmic decision-making.
Leveraging the “Titanic” Dataset from Hugging Face for Advanced Analysis
Hugging Face provides a multitude of public datasets, including the “Titanic” dataset. This dataset contains passenger details such as age, gender, passenger class, and survival status. To perform advanced analysis, we first load and inspect the dataset:
import pandas as pdurl ="https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"df = pd.read_csv(url)df.head()
PassengerId
Survived
Pclass
Name
Sex
Age
SibSp
Parch
Ticket
Fare
Cabin
Embarked
0
1
0
3
Braund, Mr. Owen Harris
male
22.0
1
0
A/5 21171
7.2500
NaN
S
1
2
1
1
Cumings, Mrs. John Bradley (Florence Briggs Th...
female
38.0
1
0
PC 17599
71.2833
C85
C
2
3
1
3
Heikkinen, Miss. Laina
female
26.0
0
0
STON/O2. 3101282
7.9250
NaN
S
3
4
1
1
Futrelle, Mrs. Jacques Heath (Lily May Peel)
female
35.0
1
0
113803
53.1000
C123
S
4
5
0
3
Allen, Mr. William Henry
male
35.0
0
0
373450
8.0500
NaN
S
Before diving into analysis, it’s crucial to preprocess the data, particularly handling missing values. Here are some standard strategies:
Deletion: Remove rows or columns containing missing values. However, this might lead to the loss of important data.
# Deletes rows with missing valuesdf_cleaned = df.dropna()# Removes columns with missing valuesdf_cleaned = df.dropna(axis=1)df_cleaned.head()
PassengerId
Survived
Pclass
Name
Sex
SibSp
Parch
Ticket
Fare
0
1
0
3
Braund, Mr. Owen Harris
male
1
0
A/5 21171
7.2500
1
2
1
1
Cumings, Mrs. John Bradley (Florence Briggs Th...
female
1
0
PC 17599
71.2833
2
3
1
3
Heikkinen, Miss. Laina
female
0
0
STON/O2. 3101282
7.9250
3
4
1
1
Futrelle, Mrs. Jacques Heath (Lily May Peel)
female
1
0
113803
53.1000
4
5
0
3
Allen, Mr. William Henry
male
0
0
373450
8.0500
Imputation: Fill missing values with some substitute like the mean, median, or mode of the column.
# Only select numeric columnsdf_numeric = df.select_dtypes(include=[np.number])# Fill in the missing values with the median of each columndf_filled_numeric = df_numeric.fillna(df_numeric.median())# Replace numeric columns in df with df_filled_numericdf[df_filled_numeric.columns] = df_filled_numericdf.head()
PassengerId
Survived
Pclass
Name
Sex
Age
SibSp
Parch
Ticket
Fare
Cabin
Embarked
0
1
0
3
Braund, Mr. Owen Harris
male
22.0
1
0
A/5 21171
7.2500
NaN
S
1
2
1
1
Cumings, Mrs. John Bradley (Florence Briggs Th...
female
38.0
1
0
PC 17599
71.2833
C85
C
2
3
1
3
Heikkinen, Miss. Laina
female
26.0
0
0
STON/O2. 3101282
7.9250
NaN
S
3
4
1
1
Futrelle, Mrs. Jacques Heath (Lily May Peel)
female
35.0
1
0
113803
53.1000
C123
S
4
5
0
3
Allen, Mr. William Henry
male
35.0
0
0
373450
8.0500
NaN
S
Prediction: Use sophisticated methods such as regression or model-based methods to predict missing values.
In the Titanic dataset, the ‘Age’ column contains missing values. Let’s impute these with the median:
With the cleaned and processed data, we can proceed with our analysis and visualization.
Understanding Nominal Data
Nominal data comprises categorical variables without a specific order or priority. This qualitative data type is often used for labeling variables that lack a numerical value. In the Titanic dataset, ‘sex’ and ‘embarked’ are examples of nominal data.
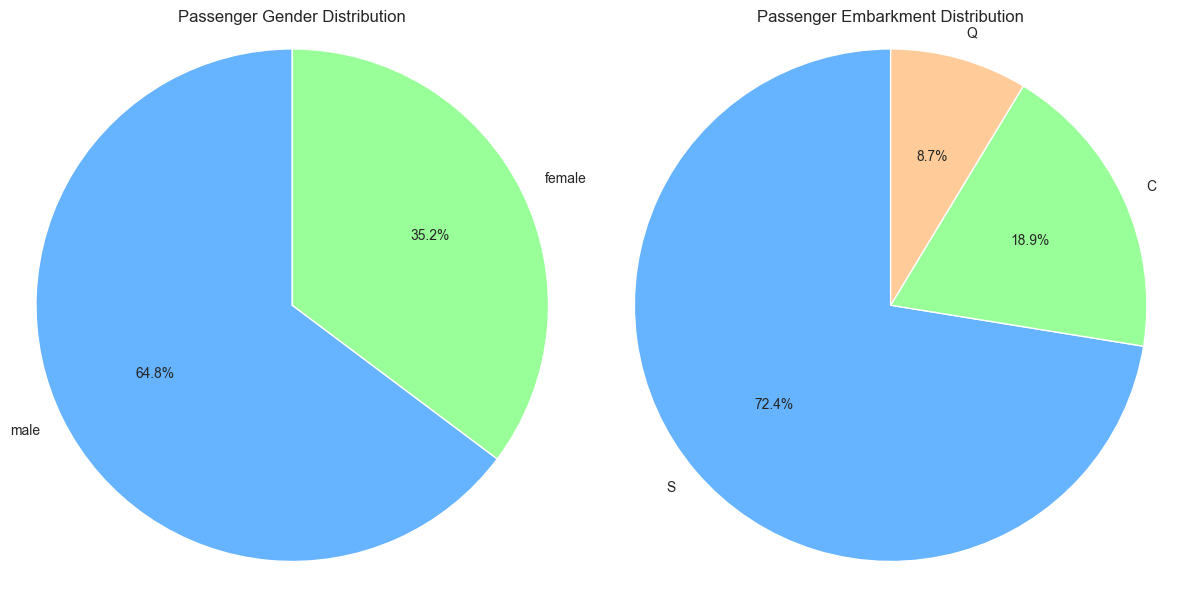
‘Sex’: This column consists of two categories: ‘male’ and ‘female’. No hierarchy or order exists in this data.
‘Embarked’: This column includes three categories: ‘S’, ‘C’, and ‘Q’, corresponding to Southampton, Cherbourg, and Queenstown. Similar to ‘sex’, this is merely a label with no hierarchical order.
Analysis of nominal data typically involves determining frequencies and percentages. For instance, with the Titanic dataset, we might be interested in the distribution of passengers by gender or departure location. Visualizations like count plots can illustrate the proportion of male to female passengers, or the likelihood of passenger departure points.
Why is nominal data analysis useful? This information can contribute to deeper analysis or predictive models. For example, if we discover that women passengers had a higher survival rate, our model could consider this. Likewise, if Cherbourg passengers were more likely to survive, our model might factor this in.
Essentially, this analysis provides insights into the basic passenger characteristics and might reveal factors that impact their survival rates.
# @title #### Nominal Chartsimport seaborn as snsimport matplotlib.pyplot as pltfig, axes = plt.subplots(1, 2, figsize=(12, 6)) # 1 row, 2 columns# Warna untuk pie chartcolors = ['#66b3ff','#99ff99','#ffcc99','#c2c2f0','#ffb3e6']# Pie chart untuk 'Sex'sex_counts = df['Sex'].value_counts()axes[0].pie(sex_counts, labels=sex_counts.index, autopct='%1.1f%%', startangle=90, colors=colors)axes[0].set_title('Passenger Gender Distribution', fontsize=12)# Pie chart untuk 'Embarked'embarked_counts = df['Embarked'].value_counts()axes[1].pie(embarked_counts, labels=embarked_counts.index, autopct='%1.1f%%', startangle=90, colors=colors)axes[1].set_title('Passenger Embarkment Distribution', fontsize=12)# Equal aspect ratio ensures that pie is drawn as a circleaxes[0].axis('equal')axes[1].axis('equal')plt.tight_layout()plt.show()
Exploring Ordinal Data
Ordinal data is a kind of categorical data featuring a specific order or hierarchy. An instance of ordinal data from the Titanic dataset is the ‘pclass’ column, representing the passenger class.
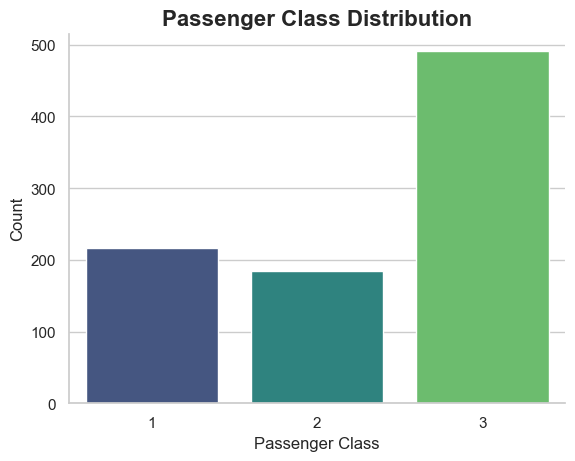
‘Pclass’: This column contains three categories: 1, 2, and 3, corresponding to Class 1, Class 2, and Class 3 aboard the Titanic. These categories have a hierarchical order, with Class 1 being superior to Classes 2 and 3, and Class 2 superior to Class 3.
Similar to nominal data, we can analyze ordinal data using frequency and percentage calculations. However, the inherent order of ordinal data allows for additional analyses not applicable to nominal data.
For instance, we might want to compare survival rates across different passenger classes. We could find that Class 1 passengers have higher survival rates than those in Classes 2 and 3. This could help determine whether passenger ‘class’ is a significant factor affecting survival rates.
Below is how we can visualize the distribution of passenger classes:
Interval data is a numerical category which has a defined order and fixed gap between values but lacks a true zero point. The ‘age’ column from the Titanic dataset is an example of interval data.
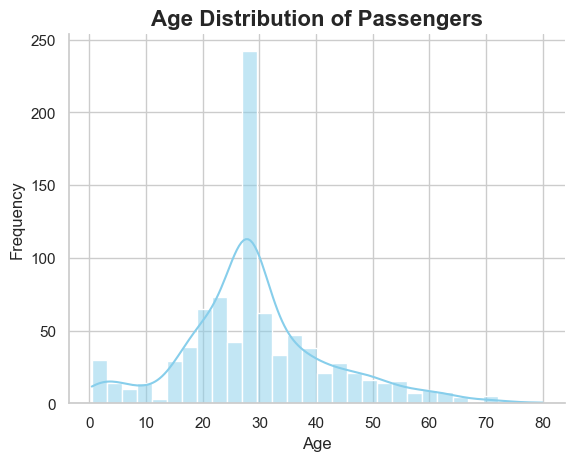
‘age’: This column’s values denote the passengers’ ages in years. The ages are in order (a passenger aged 30 is older than one aged 20), and there’s a fixed gap between values (the age difference between 20 and 30 is the same as between 30 and 40).
With interval data, we can carry out all basic mathematical operations (addition, subtraction, multiplication, and division) and descriptive statistics such as mean, median, and mode. For instance, we might want to know the average passenger age or the age distribution among passengers.
Below is how we can visualize the passengers’ age distribution:
# @title #### Interval Chartsimport seaborn as snsimport matplotlib.pyplot as plt# Atur style plotsns.set(style="whitegrid")# Membuat histogram untuk 'Age'sns.histplot(data=df, x='Age', bins=30, color='skyblue', kde=True)# Judul plot dengan font yang besar dan tebalplt.title('Age Distribution of Passengers', fontsize=16, fontweight='bold')# Label sumbu x dan y dengan font yang lebih besarplt.xlabel('Age', fontsize=12)plt.ylabel('Frequency', fontsize=12)# Hapus garis batas atas dan kanansns.despine()plt.show()
This analysis can help us understand the age distribution of passengers and may provide insight into how age might influence survival rates.
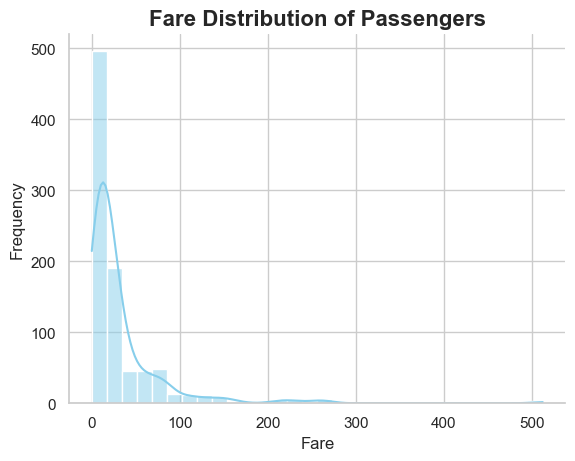
Investigating Ratio Data
Ratio data is a numerical type that possesses all the properties of interval data, i.e., a fixed order and a consistent distance between values; moreover, it features an absolute zero point. The ‘fare’ column in the Titanic dataset is a case of ratio data.
‘fare’: The values in this column depict the fare paid by each passenger. There is a defined order (a passenger paying 30 has paid more than a passenger paying 20), and a fixed gap between values (the monetary difference between 20 and 30 is the same as between 30 and 40). Furthermore, the presence of a meaningful zero point indicates the possibility of a fare being zero (the passenger paid nothing).
Like interval data, ratio data supports all basic mathematical operations and descriptive statistics, including mean, median, and mode. For instance, we might want to determine the average fare paid by passengers or the distribution of fares among passengers.
Below is how we can visualize the distribution of passenger fares:
# @title #### Ratio Chartsimport seaborn as snsimport matplotlib.pyplot as plt# Atur style plotsns.set_style("whitegrid")# Buat plotax = sns.histplot(df['Fare'].dropna(), bins=30, color='skyblue', kde=True)# Judul dan label dengan font yang besar dan tebalax.set_title('Fare Distribution of Passengers', fontsize=16, fontweight='bold')ax.set_xlabel('Fare', fontsize=12)ax.set_ylabel('Frequency', fontsize=12)# Hapus garis batas atas dan kanansns.despine(ax=ax, top=True, right=True)plt.show()
This analysis can help us understand the distribution of passenger fares and may provide insight into how fares might affect survival rates.