!pip install gensim
!pip install transformersSecond architecture: Using Word Embedding for sentiment classification
The goal of learning with this second architecture is to understand how word embedding can create semantic relations between word. We’ll use RNN architecture later to utilize word embedding to the fullest. From the intuition to the math, understanding word embedding concept and basic RNN architecture hopefully can cater your thirst on how can a model really understand a sentence.
Word Embedding: Every word has their own data
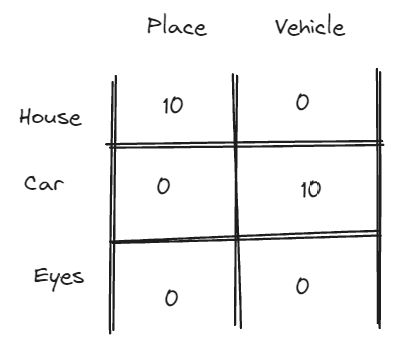
We have already learned above intuition that word embedding is like “scorecard” for every single word. Utilizing word embedding is really about understanding that every single words can contain their own information, whether it’s about gender, about their grammatical rules, about their meaning, etc.
#@title Download and load the word embedding
#@markdown We separated the download and the loading of the word embedding so you can execute below visualization, similarity calculation, etc faster without having to keep redownloading
import os
import numpy as np
import requests, zipfile, io
def download_and_unzip_embeddings(url, directory):
print(f'Downloading and unzipping embeddings...')
r = requests.get(url)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall(path=directory)
def load_glove_embeddings(path, url):
# If file doesn't exist, download and unzip it
if not os.path.isfile(path):
download_and_unzip_embeddings(url, path.rsplit('/', 1)[0])
with open(path, 'r') as f:
embeddings = {}
for line in f:
values = line.split()
word = values[0]
vector = np.asarray(values[1:], dtype='float32')
embeddings[word] = vector
return embeddings
# URL of GloVe embeddings and the path - replace with your actual URL
url = 'http://nlp.stanford.edu/data/glove.6B.zip'
path = 'glove.6B/glove.6B.300d.txt'
embeddings = load_glove_embeddings(path, url)
from gensim.models import Word2Vec, KeyedVectors
from sklearn.manifold import TSNE
import numpy as np
import pandas as pd
import plotly.graph_objects as go
def load_glove_model(glove_input_file):
glove_model = KeyedVectors.load_word2vec_format(glove_input_file, binary=False)
return glove_model
# Convert the GloVe file format to word2vec file format
glove_input_file = 'glove.6B/glove.6B.50d.txt'
word2vec_output_file = 'glove.6B/glove.6B.50d.txt.word2vec'
from gensim.scripts.glove2word2vec import glove2word2vec
glove2word2vec(glove_input_file, word2vec_output_file)
model = load_glove_model(word2vec_output_file)DeprecationWarning:
Call to deprecated `glove2word2vec` (KeyedVectors.load_word2vec_format(.., binary=False, no_header=True) loads GLoVE text vectors.).
Scatterchart for words relation in GloVe word embedding

One of the most popular word embedding dictionary is GloVe, Global Vectors for word representation. GloVe is basically an existing dictionary of word embeddings in English that collecting hundreds of thousands to millions of vocabularies and map every single one of them to their dedicated matrix of word embeddings.
NLP and words: The problem of finding relations
We’ll talk more about how a word can be attached to a context later when we’re learning how to generate a word embedding, but in broad sense a word embedding is generated by learning word relations.
For now let’s see below scatterplot to see a single word and what words that GloVe learned that related to that word.
#@title Scatterplot of word relations
word = "king" #@param
find_nearest = 50
# The most_similar method and extraction of word vectors is not mentioned.
# You'll have to implement this yourself or use an API like gensim or Spacy that provides this functionality.
result = model.most_similar(word, topn=find_nearest)
word_labels = [word for word, similarity in result]
similarity_scores = [similarity for word, similarity in result]
word_labels.append(word)
word_vectors = model[word_labels]
# Below part of the code assumes word_labels and word_vectors are correctly fetched and prepared.
tsne = TSNE(n_components=2)
reduced_vectors = tsne.fit_transform(word_vectors)
df = pd.DataFrame(reduced_vectors, columns=["tsne1", "tsne2"])
df['word'] = word_labels
df['is_input_word'] = (df['word'] == word)
df_input_word = df[df['is_input_word']]
df_similar_words = df[~df['is_input_word']]
fig = go.Figure()
fig.add_trace(go.Scatter(
x=df_similar_words["tsne1"],
y=df_similar_words["tsne2"],
mode='markers+text',
marker=dict(
size=8,
color='rgba(152, 0, 0, .8)',
),
text=df_similar_words['word'],
textposition='top center',
name='Similar words'
))
fig.add_trace(go.Scatter(
x=df_input_word["tsne1"],
y=df_input_word["tsne2"],
mode='markers+text',
marker=dict(
size=12,
color='rgba(0, 152, 0, .8)',
),
text=df_input_word['word'],
textposition='top center',
name='Input word'
))
fig.update_layout(
title_text=f'2D visualization of word embeddings for "{word}" and its similar words',
xaxis=dict(title='t-SNE 1'),
yaxis=dict(title='t-SNE 2'))
fig.show()
# Similarity Bar chart only for similar words
fig2 = go.Figure(data=[
go.Bar(x=word_labels[:find_nearest], y=similarity_scores,
text=similarity_scores, textposition='auto')
])
fig2.update_layout(
title_text=f'Bar chart showing similarity scores of top {find_nearest} words similar to {word}', # 'words' is changed to 'word'
xaxis=dict(title='Words'),
yaxis=dict(title='Similarity Score'))
fig2.show()As you can see above word “king”, GloVe word embedding create relations from that word to other words that relate to that word:
- “queen” is a term for king’s wife
- “empire”, “kingdom” are terms that talks about king’s territory of power
- “death” are a term that meant that a king can be deceased
And so on. Of course it’s hard to really pin point what exactly the context that GloVe understand for a single word, why exactly does GloVe “think” that a word is related to another word because GloVe word embeddings are created by a neural network - which means that a word embedding is mostly lack of explainability in their creation of relations, we can only guess.
Similarity in context
Before we continue, one term that you should know is that when we check how a word related to another word, the term is mostly referred to “similarity”. Similarity means how similar that the given word to the context for another word, in our given context on NLP similarity mostly means:
- How often two words come together in a sentence near each other
- How two words even when not often come together, mostly paired with similar words, ie: car often comes with the word drive, and bus also comes with the word drive.
Of course we’ll dive in further into the concept later in their dedicated section. Reminder that we use data from Wikipedia to generate word embedding, more text to gather from can give better context and this lack of source can weakened the word embedding accuracy on giving context to each words.
Multiple words relation
We can also try to visualize the word relation for several words at once, so we can know what GloVe word embedding thinks how some words relate to the other.
You can try below demonstration and feel free to play with the input. You might notice that you can add negative words as well to make sure some words won’t be included to your plot.
#@title Multiple words similarity
import plotly.graph_objects as go
words_str = "dog,cat" # @param
neg_words_str = "man" # @param
find_nearest = 50
# Parse array from comma-delimited string
words = words_str.split(',')
neg_words = neg_words_str.split(',')
# Filter out empty strings
words = [word for word in words if word]
neg_words = [word for word in neg_words if word]
# Use the most_similar method to get the top 'find_nearest' words that are most similar to your list of words
result_positive = model.most_similar(positive=words, topn=find_nearest, negative=neg_words)
word_labels = [word for word, similarity in result_positive]
similarity_scores = [similarity for word, similarity in result_positive]
# Extend labels and vectors for positive results
word_labels.extend(words)
# Extract vectors for words
word_vectors = model[word_labels]
# Reduce dimensionality for visualization
tsne = TSNE(n_components=2)
reduced_vectors = tsne.fit_transform(word_vectors)
# Prepare DataFrame
df = pd.DataFrame(reduced_vectors, columns=["tsne1", "tsne2"])
df['word'] = word_labels
df['is_input_word'] = df['word'].isin(words)
df_input_word = df[df['is_input_word']]
df_similar_words = df[~df['is_input_word']]
# Word embedding scatter plot
fig = go.Figure()
# Similar words
fig.add_trace(go.Scatter(
x=df_similar_words["tsne1"],
y=df_similar_words["tsne2"],
mode='markers+text',
marker=dict(
size=8,
color='rgba(152, 0, 0, .8)',
),
text=df_similar_words['word'],
textposition='top center',
name='Similar words'
))
# Input words
fig.add_trace(go.Scatter(
x=df_input_word["tsne1"],
y=df_input_word["tsne2"],
mode='markers+text',
marker=dict(
size=12,
color='rgba(0, 152, 0, .8)',
),
text=df_input_word['word'],
textposition='top center',
name='Input words'
))
fig.update_layout(
title_text=f'2D visualization of word embeddings for {words} and their most similar words',
xaxis=dict(title='t-SNE 1'),
yaxis=dict(title='t-SNE 2'))
fig.show()
# Similarity Bar chart only for similar words
fig2 = go.Figure(data=[
go.Bar(x=word_labels[:find_nearest], y=similarity_scores,
text=similarity_scores, textposition='auto')
])
fig2.update_layout(
title_text=f'Bar chart showing similarity scores of top {find_nearest} words similar to {words}',
xaxis=dict(title='Words'),
yaxis=dict(title='Similarity Score'))
fig2.show()Dimensionality Reduction
Dimensionality reduction
Remember that in reality word embedding’s dimension is a lot larger than 2 dimension (our above glove word embedding have 100 dimensions per word), what we did above is called dimentionality reduction using T-SNA. Dimensionality reduction can be simplified for the intuition using below analogy:
We live in 3 dimension world, we often “reduce the dimension” of what we see in nature by taking a photo (the photo is 2 dimension)
Above analogy can help you to understand that: - We can capture higher dimension vector to lower dimension - We will lose lots of information along the way. 2 dimension can’t clearly provide context missing from the our real world such as depth, we can’t see what is behind objects on our photo, etc.
Reducing dimensions == removing context
Remember previous intuition that when we do embedding each dimension is embedded with different kind of context? If we reduce any dimension like previous scatter plot we’ll find that lots of context will be missing.
Curse of dimensionality
The problem in the finding similar data is not as simple as finding your key that were lost in your room. Come curse of dimensionality:
Imagine you’re playing hide-and-seek with your friend in a long straight hallway with doors on either side. Each door leads to a room. Although it might take some time, you have only one direction to go – you can walk one way, then back the other way to check each room systematically. This is the equivalent to a problem of one dimension.
Now, imagine if your friend could be hiding in any room in a single floor of a building, but the floor has a maze of lots of directions to go, not a single straight hallway anymore. Now you have more places to potentially look for your friend because the hiding space is wider and longer. You are dealing with two dimensions in this case (length and width of the building).
Let’s go a step further. Your friend could be in any room of a massive multi-storey building with numerous rooms on each floor. Now, your friend has a lot more possible hiding spots because you’re not only searching across the length and width of the building, but also high and low up the multiple floors. This is an example of a problem with three dimensions (length, width, and height of the building).
The curse of dimensionality creates a complex problem when we want to search for similarity because as you can see above, adding dimension adding multitude of complexity.
This is the reason if you click play on our visualizations above, the value that are near your requested query keeps changing: We (data scientist) found some ways to search similarity quickly, but it’s almost impossible to really know if it’s really the nearest - we just guessing that it’s the most likely to be the most similar, but the computational resource to ensure that it’s really the nearest neighbor is expensive.
This concept is one of the reason why when we talk to ChatGPT we might have different answers from the same query.
Context-aware embedding vs static embedding
The last thing that we’ll learn right now for the intuition on word embedding is the difference of context-aware embeddings and static embeddings.
Context-aware embedding is a word embedding that’s generated per sentence input, for example:
“I love this bat, because its grip is perfect for my baseball match.”
A “bat” can be referred to many context. A static word embedding might be able to contain several context of a “bat”, but context-aware embedding is focused on understanding the whole input, the whole sentence first then giving word embedding per word that is focused on that sentence, so the “bat” here will refer to a baseball bat, and the model won’t consider other context for “bat”.
The example for static word embedding is GloVe, which we already learned. And the example for context-aware embedding is BERT, which we’ll dive in further in it’s dedicated section.
#@title Context-aware embedding demo
from transformers import AutoTokenizer, AutoModel
import torch
from scipy.spatial.distance import cosine
import plotly.graph_objects as go
tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased', use_fast=True)
bert_model = AutoModel.from_pretrained('distilbert-base-uncased')
def embed_text(text):
# Encode text
inputs = tokenizer(text, return_tensors='pt')
# Compute token embeddings
outputs = bert_model(**inputs)
# Retrieve the embeddings of the mean tokens
embeddings = outputs.last_hidden_state.mean(dim=1).detach().numpy()
return embeddings
def calculate_similarity(embedding_1, embedding_2):
# Flatten the embeddings to 1D before comparing using cosine distance
return 1 - cosine(embedding_1.flatten(), embedding_2.flatten())
def plot_comparison(word, compare_1, compare_2, similarity_1, similarity_2):
fig = go.Figure(data=[
go.Bar(name=compare_1, x=[word], y=[similarity_1]),
go.Bar(name=compare_2, x=[word], y=[similarity_2])
])
# Customize aspect
fig.update_layout(barmode='group')
fig.show()
# Your inputs
#@markdown The text input
text = "I love this bat, because its grip is perfect for my baseball match." #@param
#@markdown the word to compare
word = "bat" #@param
#@markdown context to compare
compare_1 = "animal bat"#@param
compare_2 = "baseball bat"#@param
word_embedding = embed_text(text + " " + word)
compare_1_embedding = embed_text(compare_1)
compare_2_embedding = embed_text(compare_2)
similarity_1 = calculate_similarity(word_embedding, compare_1_embedding)
similarity_2 = calculate_similarity(word_embedding, compare_2_embedding)
plot_comparison(word, compare_1, compare_2, similarity_1, similarity_2)Up next: Understanding the math
We’ve already learned how basic machine learning model that doesn’t use deep learning understand how to classify a sentence, and we’re learning the lack of “context” understanding when we’re not using neural netwok. Then we’re learning about the intuition of how word embedding works.