!pip install transformersIntuition
Welcome to NLP learning, we’ll start warming up with just mostly about intuition that you should understand about how natural language processing works, what is preprocessing and how to preprocess our data, then we’ll see the intuition about how several architecture works behind the scene, and much more.
The Black Box

Natural language processing is a concept of understanding “natural language” ( which basically means “human language”) and making sure a machine can understand that “natural language”. But how can a machine understand humand language, let alone answering it like ChatGPT above?
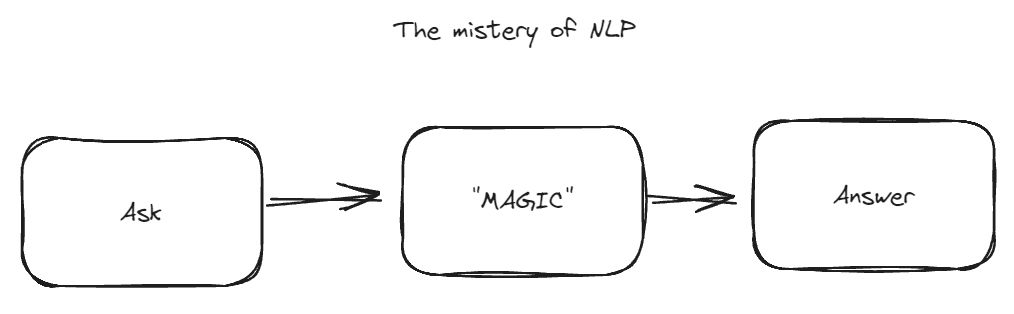
Machine only understand numbers

We’ve learned machine learning so far, and what is one of the most oversimplification but kinda true about machine learning? When it comes to inferring, it’s basically just a giant calculator that keep doing matrix multiplication, activation, etc.
So when we’re facing our computer to learn about language, we need to convert them into numbers first. For that later we’ll learn about:
- Preprocessing
- Tokenization
- Word embedding
After the “Magic” process (that of course we’ll learn more later), we’ll need to convert the output process back to human language. This process of converting numbers back to human language is mostly using fully-connected layer, things that we have learned again and again, not that complex right? 😉
The process of answering
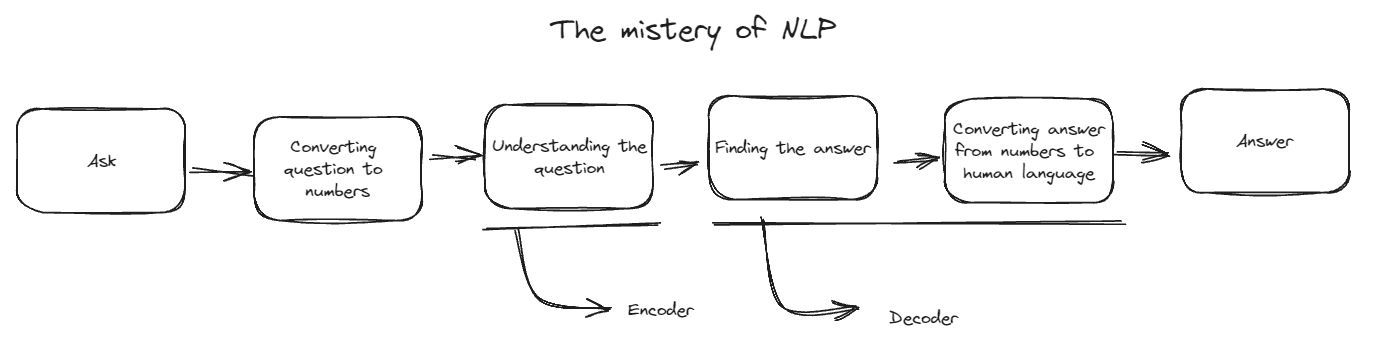
Now let’s uncover more “magic”. In general the magic itself can be divided into two categories: Encoder (The part of where the model try to understanding the question) and decoder (The part where the model finding the answer and converting the answer which previously only can be understand by our modal back to human words).
Encoder
Encoder’s position in NLP is to “encode context from human input”, which translates to “making human language to make it digestable by our model. So for lots of architecture -despite the modern architecture that lacking encoder layer- encoder is a part of”converting” input to a vector, array of numbers that can be processed further after that.
So a sentence can be summarized into an array of numbers that later can be processed further by the machine, but if zoomed in further even every single words can be summarized into an array of numbers, which is called “Word embedding” which we’ll learn right after this.
A sentence have lots of words, every single words have their own array of numbers that can be understood by a machine, the encoder is a way to summarize those words into another array of numbers that encapsulate the whole sentence meaning.
#@title Encoded text
from transformers import BartTokenizer, BartModel
# Initialize tokenizer and model
tokenizer = BartTokenizer.from_pretrained('facebook/bart-large')
model = BartModel.from_pretrained('facebook/bart-large')
# Input text
text = "Hey, how are you doing today?" #@param
# Encode text
encoded_input = tokenizer(text, return_tensors='pt')
# Get embeddings
embeddings = model(**encoded_input)['last_hidden_state']
embeddingstensor([[[ 0.3529, 0.5034, -1.6365, ..., 0.4680, 0.7314, 0.4178],
[ 0.3529, 0.5034, -1.6365, ..., 0.4680, 0.7314, 0.4178],
[ 1.7981, 1.9646, -0.3734, ..., 0.1334, -0.3966, -0.4826],
...,
[-0.1854, 4.0069, -0.2969, ..., 0.2142, 0.0490, 0.8782],
[ 0.2307, 4.7543, -0.8947, ..., 1.2735, 1.1160, -0.8490],
[-0.4442, 1.4159, -0.4588, ..., 0.8986, 0.8376, 0.3417]]],
grad_fn=<NativeLayerNormBackward0>)NLP model == Complex calculator
If you run above code, you’ll see that above sentence are translated into numbers that can later be processed further into our model. So by seeing array of matrix above hopefully you can be more understand that the basis of NLP is basically lots and lots of matrix operation: It’s basically a really complex calculator.
Word embedding - Where every words containing a lot of contexts
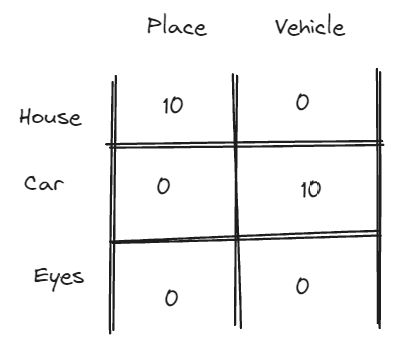
Every single words in NLP refer to a word embedding, a word embedding basically an array of numbers that represent the word context, that every single word embedding can contains hundreds or thousands of dimension that are containing different “context”.
So word like “horse” for example, have a word embedding that refer to that exact word that more or less look like: “[0, 3213, 732 ..,943]”.
To not be ahead of ourselves, consider when we want to complete below sentence:
Andi walks into his own ___
When we’re seeing above sentence we might talk more about: - Places - Vehicles
So we’ll find in words that contains high value in dimension that refer to that. We might find that the word book, glass, microphone, ear, eye, is really unlikely to be the answer of above sentence, as it’s not related to places, or vehicles, so the scores should be really low or even negative.
But for the words like garden, car, house, would be more likely to complete above sentence, so the score would be higher.
So in NLP, multidimensionality refers to every word have their own “score-card” which behave like scoring system how a dimension reflect to certain context so when we need an answer we can just “found them in the referred context”.
Of course it’s a really high-level intuition which we’ll learn more about when we touch word embedding 😀
Heads up: In reality word-embedding might not only be a single word have single embedding, but can be divided more to “sub-words”, which is “parts-of-words”, a word divided to several parts such as “hiking” can be divided to “hike-ing”.
#@title Get a word embedding
import os
import numpy as np
import requests, zipfile, io
def download_and_unzip_embeddings(url, directory):
print(f'Downloading and unzipping embeddings...')
r = requests.get(url)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall(path=directory)
def load_glove_embeddings(path, url):
# If file doesn't exist, download and unzip it
if not os.path.isfile(path):
download_and_unzip_embeddings(url, path.rsplit('/', 1)[0])
with open(path, 'r') as f:
embeddings = {}
for line in f:
values = line.split()
word = values[0]
vector = np.asarray(values[1:], dtype='float32')
embeddings[word] = vector
return embeddings
# URL of GloVe embeddings and the path - replace with your actual URL
url = 'http://nlp.stanford.edu/data/glove.6B.zip'
path = 'glove.6B/glove.6B.50d.txt'
embeddings = load_glove_embeddings(path, url)
# To get a word's embedding
word = 'computer' #@param
embedding_vector = embeddings.get(word)
# If the word doesn't exist in the dictionary, `get` method will return None.
if embedding_vector is not None:
print(embedding_vector)
else:
print(f"'{word}' not found in the dictionary.")[ 0.079084 -0.81504 1.7901 0.91653 0.10797 -0.55628 -0.84427
-1.4951 0.13418 0.63627 0.35146 0.25813 -0.55029 0.51056
0.37409 0.12092 -1.6166 0.83653 0.14202 -0.52348 0.73453
0.12207 -0.49079 0.32533 0.45306 -1.585 -0.63848 -1.0053
0.10454 -0.42984 3.181 -0.62187 0.16819 -1.0139 0.064058
0.57844 -0.4556 0.73783 0.37203 -0.57722 0.66441 0.055129
0.037891 1.3275 0.30991 0.50697 1.2357 0.1274 -0.11434
0.20709 ]As we see above, a “computer” can be embedded into numbers that each dimension contain some context of “computer”. To show above example we use 50 dimension from word embedding named “GloVe”, but in reality even in GloVe they have variation of number of dimensions like 100 dimensions, 200 dimensions, even 300 dimensions, when the more dimension can contain more context of a word.
One word at a time
When we’re talking about question and answering like GPT model, we can see that our input is being answered one at a time.
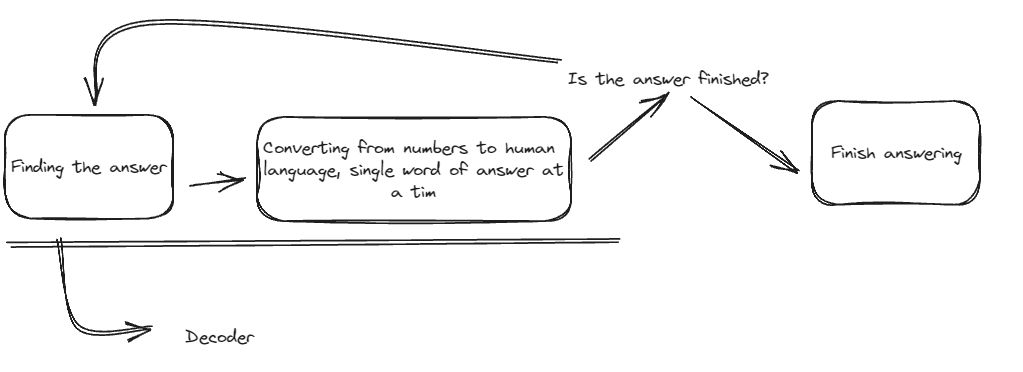
It’s simply because decoder mostly work at one-word-at-a-time. So after they got their encoded input, it will process what output that it thinks the best, one-word-at-a-time.
After a single word is finished, the model will check if it’s the last word or not, if not, then the next decoder process is continue.
End-to-end Process Intuition
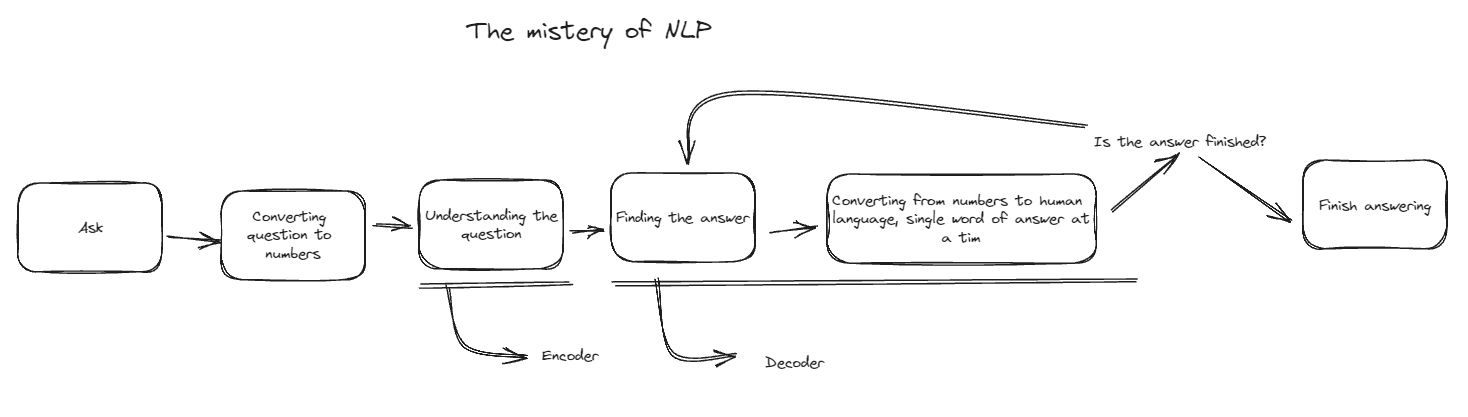
So above diagram is a really high overview of NLP’s intuition. Our journey in learning NLP, most of it can be categorized into any of above steps.
Remember that some of NLP architecture only use above categorization until “Undestanding the question”.
In more classic architecture the concept of encoder isn’t really exist, so the concept of “Understanding the question” won’t use encoder.
In modern architecture there’s a concept called “Self-Attention” that even can skip the whole concept of “Encoder” and just straight to “Decoder”.