Weights & Biases (WanDB) is a developer-oriented toolset, designed specifically for machine learning. It helps monitor and visualize the model’s training process and its performance in a more intuitive way. WanDB provides a centralized platform where teams can log, share, and collaborate on their machine learning projects, making it easier to compare different runs and models’ performance.
B. Why use WanDB?
There are several reasons why WanDB stands out as a preferred tool for machine learning projects:
Track and Visualize Models: WanDB provides a simple way to track every detail of your experiment, providing real-time visualization of your models’ training and results.
Hyperparameter Optimization: With WanDB’s Sweeps, you can automate hyperparameter tuning and explore the parameter space more efficiently to optimize your model’s performance.
Collaboration: WanDB makes it easy to share your experiment results with colleagues and the community, fostering collaboration and knowledge sharing.
Reproducibility: By logging all the metadata from your runs, WanDB helps maintain the reproducibility of your experiments, which is crucial in machine learning projects.
C. Understanding the Importance of Monitoring and Improving Model Training
Monitoring and improving model training is an essential part of the machine learning workflow.
Monitoring: By keeping track of various metrics such as loss and accuracy during the training process, you can understand how well your model is learning and whether it’s improving over time. This can help you detect issues like overfitting or underfitting early on and take corrective actions.
Improving: Once you monitor your model’s performance, the next step is to improve it. This could involve tweaking the model’s architecture, optimizing hyperparameters, or using more/ different data for training. Tools like WanDB make it easier to experiment with these aspects and track the impact of each change, thereby helping you build better models.
Setting up WanDB
A. Account Setup
To get started with WanDB, you need to create a free account:
Visit the official Weights & Biases website: wandb.ai
Click on Sign Up at the top right corner of the home page.
You can opt to sign up using a GitHub, Google, or LinkedIn account. Alternatively, sign up using your email address and a password.
You will see your API Keys/Token, you will need it. If you didn’t save it or you lost it, you can look it up in User Settings.
B. Installing the Wandb library
Once you’ve set up your account, you need to install the Wandb library in your Python environment. It can be installed using pip:
pip install wandb
Or with conda:
conda install -c conda-forge wandb
Ensure you have the latest version of the library for optimal functionality.
C. Initializing WanDB in Your Code
After installing the Wandb library, you need to import it and initialize it within your project. Start by importing wandb:
import wandb
Then, initialize wandb with wandb.init(). You can pass several optional parameters to wandb.init(), such as:
project: The name of the project where you’re logging runs. This could be any string, and a new project will be created if it doesn’t already exist.
entity: The username or team name under which the project is to be created.
An example of initializing Wandb for a project named ‘my_project’ under username ‘my_username’ would be:
After running wandb.init(), a new run will be created on the WanDB website, where you can track your model’s progress, visualize results, and more.
Let’s create a simple project that utilizes WandB (Weights and Biases) for experiment tracking. This project will be about classifying the CIFAR-10 dataset using a Convolutional Neural Network (CNN) implemented in Pytorch.
Project: CIFAR-10 Image Classification with Pytorch and WandB
Overview
The CIFAR-10 dataset consists of 60,000 32x32 color images in 10 classes, with 6,000 images per class. The goal of this project is to classify the images into these classes.
We will use a Convolutional Neural Network (CNN) in Pytorch to perform this classification task. The model’s performance will be logged and visualized using WandB, a tool for machine learning experiment tracking.
Steps
1. Setting Up the Environment
Install the necessary libraries.
!pip install torch torchvision wandb
Requirement already satisfied: torch in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (2.0.1)
Requirement already satisfied: torchvision in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (0.15.2)
Requirement already satisfied: wandb in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (0.16.4)
Requirement already satisfied: filelock in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from torch) (3.12.3)
Requirement already satisfied: typing-extensions in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from torch) (4.7.1)
Requirement already satisfied: sympy in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from torch) (1.12)
Requirement already satisfied: networkx in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from torch) (3.1)
Requirement already satisfied: jinja2 in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from torch) (3.1.2)
Requirement already satisfied: numpy in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from torchvision) (1.25.2)
Requirement already satisfied: requests in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from torchvision) (2.31.0)
Requirement already satisfied: pillow!=8.3.*,>=5.3.0 in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from torchvision) (10.0.0)
Requirement already satisfied: Click!=8.0.0,>=7.1 in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from wandb) (8.1.7)
Requirement already satisfied: GitPython!=3.1.29,>=1.0.0 in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from wandb) (3.1.36)
Requirement already satisfied: psutil>=5.0.0 in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from wandb) (5.9.5)
Requirement already satisfied: sentry-sdk>=1.0.0 in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from wandb) (1.40.6)
Requirement already satisfied: docker-pycreds>=0.4.0 in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from wandb) (0.4.0)
Requirement already satisfied: PyYAML in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from wandb) (6.0.1)
Requirement already satisfied: setproctitle in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from wandb) (1.3.3)
Requirement already satisfied: setuptools in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from wandb) (68.2.2)
Requirement already satisfied: appdirs>=1.4.3 in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from wandb) (1.4.4)
Requirement already satisfied: protobuf!=4.21.0,<5,>=3.19.0 in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from wandb) (4.24.3)
Requirement already satisfied: six>=1.4.0 in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from docker-pycreds>=0.4.0->wandb) (1.16.0)
Requirement already satisfied: gitdb<5,>=4.0.1 in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from GitPython!=3.1.29,>=1.0.0->wandb) (4.0.10)
Requirement already satisfied: charset-normalizer<4,>=2 in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from requests->torchvision) (3.2.0)
Requirement already satisfied: idna<4,>=2.5 in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from requests->torchvision) (3.4)
Requirement already satisfied: urllib3<3,>=1.21.1 in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from requests->torchvision) (2.0.4)
Requirement already satisfied: certifi>=2017.4.17 in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from requests->torchvision) (2024.2.2)
Requirement already satisfied: MarkupSafe>=2.0 in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from jinja2->torch) (2.1.3)
Requirement already satisfied: mpmath>=0.19 in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from sympy->torch) (1.3.0)
Requirement already satisfied: smmap<6,>=3.0.1 in /Users/ruangguru/Projects/ai-bootcamp/env/lib/python3.11/site-packages (from gitdb<5,>=4.0.1->GitPython!=3.1.29,>=1.0.0->wandb) (5.0.0)
[notice] A new release of pip is available: 23.3.2 -> 24.0
[notice] To update, run: pip install --upgrade pip
2. Import the Libraries
import torchfrom torch import nn, optimimport torchvisionfrom torchvision import datasets, transformsimport wandbimport torch.nn.functional as F
Evaluate the model on the test data and log the test accuracy to WandB.
correct =0total =0with torch.no_grad():for data in testloader: images, labels = data outputs = model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item()print('Accuracy of the network on the test images: %d%%'% (100* correct / total))wandb.log({'Test Accuracy': 100.0*correct/total})
Accuracy of the network on the test images: 52 %
This section of the code calculates the accuracy of the model on the test set and logs this test accuracy to WandB for visualization and tracking.
At this point, you can go to the WandB website, navigate to your project, and see a live visualization of your model’s loss and accuracy throughout the training process. This helps to understand how well the model is learning and provides insights for further improvements.
Finally, don’t forget to close your WandB run after you’re done:
This ensures all resources are properly freed and all logs are uploaded to the WandB server. This step is crucial to make sure all your model training progress and metrics are properly saved and can be reviewed later in the WandB dashboard.
Basic Concepts of WanDB
Here’s what the WanDB dashboard looks like:
A. Projects
In Wandb, a project is a collection of related machine learning experiments (known as “runs”). It provides a shared space where you and your team can compare results, share insights, and discuss potential improvements. Each project has a dedicated page on the Wandb web application, showcasing visualizations, comparisons, and other useful metrics. We set the project name when we do wandb.init() in Step-3 above.
B. Runs
A run in Wandb is a single execution of your machine learning script. During a run, you can log various metrics, such as loss and accuracy, system performance data, and even media like images or 3D objects. Each run gets its page in the Wandb web application, where you can view and analyze logged data.
As you can see from the screenshot of the WanDB dashboard, on the left we have 5 runs in our project.
C. Artifacts
Artifacts in Wandb are used to handle version control of datasets, models, and other result files from runs. They help to track the inputs and outputs of your runs, providing a clear and useful lineage of your models and data. For example, an input artifact could be your training dataset, while output artifacts could be your trained model or predictions.
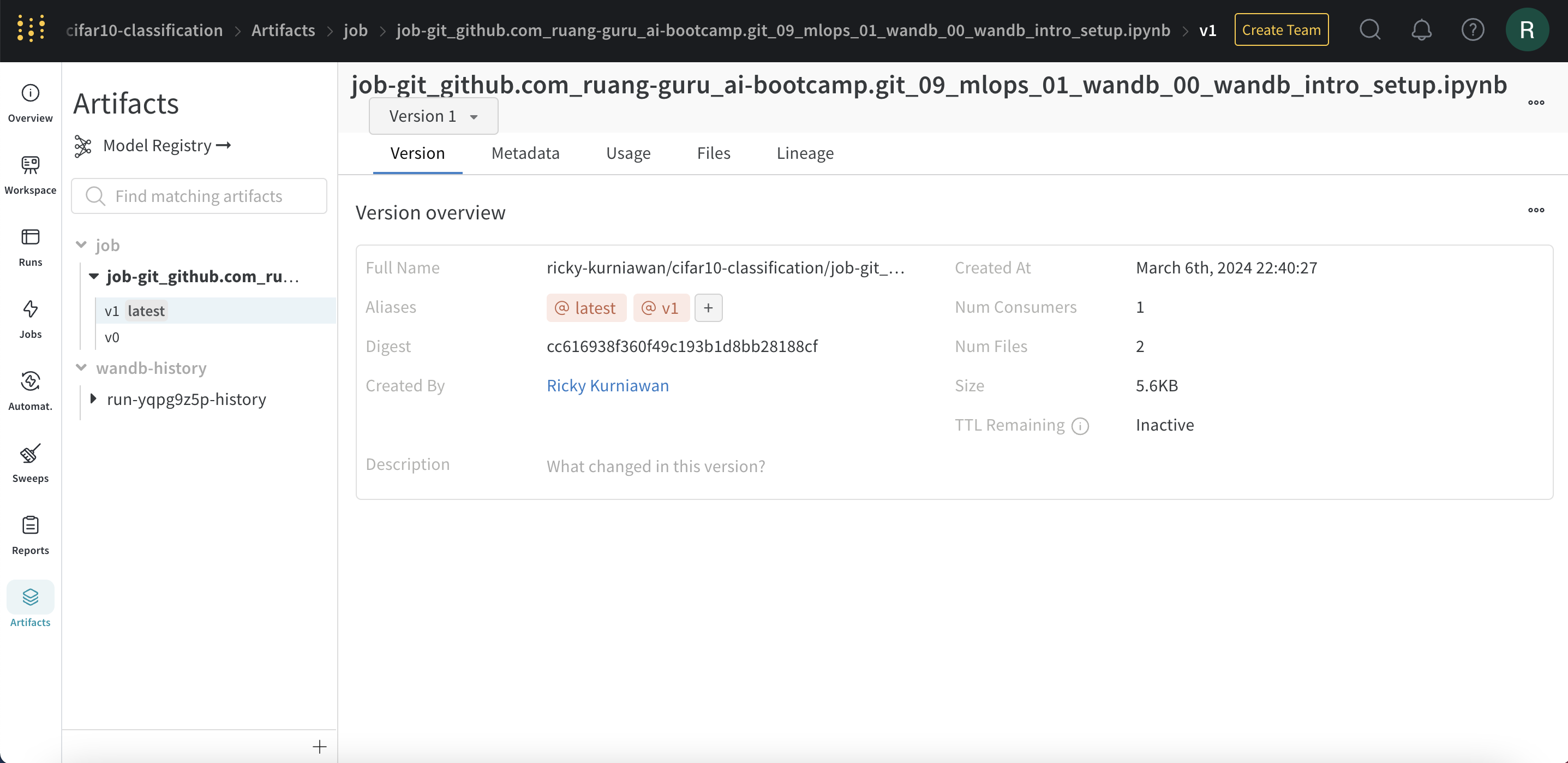
On the left you can click on the Artifacts navigation icon which will take you to:
In this case, the artifact is a Jupyter notebook file (job-git_github.com_ruang-guru_ai-bootcamp.git_09_mlops_01_wandb_00_wandb_intro_setup.ipynb) from the project cifar10-classification owned by the user ricky-kurniawan. The version of the artifact is specified after the colon - in this case, v1 indicates it’s the first version.
The artifact.download() command is used to download the artifact to the local machine for use in the current run.
In the “Used By” section, the listed items are the runs that have used this artifact. For example, the run proud-salad-5 used this artifact. Information such as the run’s performance metrics, the project, the user, the artifact used, and the time of artifact creation is displayed.
In this case, run-yqpg9z5p-history:v0 is an output artifact of the run. This run history artifact contains information about the run, such as the logged metrics. This artifact is created automatically by W&B when you log metrics or other information during a run. This allows you to revisit the specifics of a run, analyze the performance, and potentially identify areas for improvement or further exploration.
D. Sweep
Sweep is a feature in Wandb for hyperparameter optimization. A sweep involves a set of runs, each with different hyperparameters, allowing you to explore a range of possibilities and identify the best parameters for your model. Wandb automates this process, generating a set of permutations of hyperparameters (based on a configuration file you create), running them, and logging the results. This makes it easier to optimize your model’s performance.
Let’s try doing a Sweep using our CIFAR-10 Project.
1. Setting Up the Configuration
First, we need to create a configuration for our sweep. This configuration will specify the range and distribution of hyperparameters for the sweep. Here’s a basic example:
In this configuration, we’re specifying that we want to use a random search method (other options are grid for grid search and bayes for Bayesian optimization), and that our goal is to maximize accuracy. We’re also specifying the range of values for the hyperparameters that we want to optimize: epochs, batch size, and learning rate.
Create sweep with ID: kqyufn28
Sweep URL: https://wandb.ai/ricky-kurniawan/cifar10-classification/sweeps/kqyufn28
This command initializes the sweep and returns a sweep ID. This ID uniquely identifies the sweep in WandB.
3. Define the Train Function
Next, we need to modify the training function to accept configurations and log them to WandB. Add the following lines at the beginning of the function:
In this function, wandb.init() is called with the sweep configuration to start a new run. wandb.config is then used to access the hyperparameters for the current run.
For the purpose of teaching, we are limiting the run to a maksimum of 5. Naturally you should let the sweep run and try out all possible combinations which may take a long time. You can safely remove all lines containing “global_counter” for real case study.
4. Run the Sweep
wandb.agent(sweep_id, train)
wandb: Agent Starting Run: jbxkaalg with config:
wandb: batch_size: 64
wandb: epochs: 10
wandb: learning_rate: 0.052303023093622406
wandb: Currently logged in as: ricky-kurniawan. Use `wandb login --relogin` to force relogin
Tracking run with wandb version 0.16.4
Run data is saved locally in /Users/ruangguru/Projects/ai-bootcamp/09_mlops/01_wandb/wandb/run-20240307_162427-jbxkaalg
This command will start the sweep we just defined. WandB will call the train function with the different combinations of hyperparameters defined in the sweep configuration.
Here’s what the Sweep Dashboard looks like:
We can clearly see the which combination is more effective by looking at the charts, we can then dive in to fine tune our hyperparameters.
WandB’s sweeps are a powerful tool for optimizing your model’s hyperparameters. By integrating WandB with your model training code, you can automate the process of training many models with different hyperparameters, and then easily compare their performance on the WandB’s dashboard.