%pip install elasticsearchSnapshot

Elasticsearch (Source: technocratsid.com)
Let’s think of Elasticsearch as a vast library filled with knowledge. The data in your Elasticsearch cluster are like the precious books in this library.
A Snapshot is like a detailed photocopy of every book in the library. It acts as a backup for your Elasticsearch cluster, ensuring that all the data is safely copied and stored. You might regularly create snapshots to safeguard against accidents such as a coffee spill (hardware failure) or unintentional removal of a book (accidentally deleting an index).
Before you can start making photocopies (snapshots), you need a place to store them. That’s where the Snapshot Repository comes in. It’s like a dedicated room in your library where you keep all these photocopies. Elasticsearch supports a wide variety of storage locations for your repositories, such as AWS S3, GCP Storage, Azure Storage, and more. For simplicity’s sake, in this lesson we’re going to use the easiest method - File Storage, which allows you to store the snapshots on your own computer. To set up a repository, you need to tweak the library’s blueprint (change the elasticsearch.yml configuration), and then restart the library’s operating system (restart Elasticsearch).
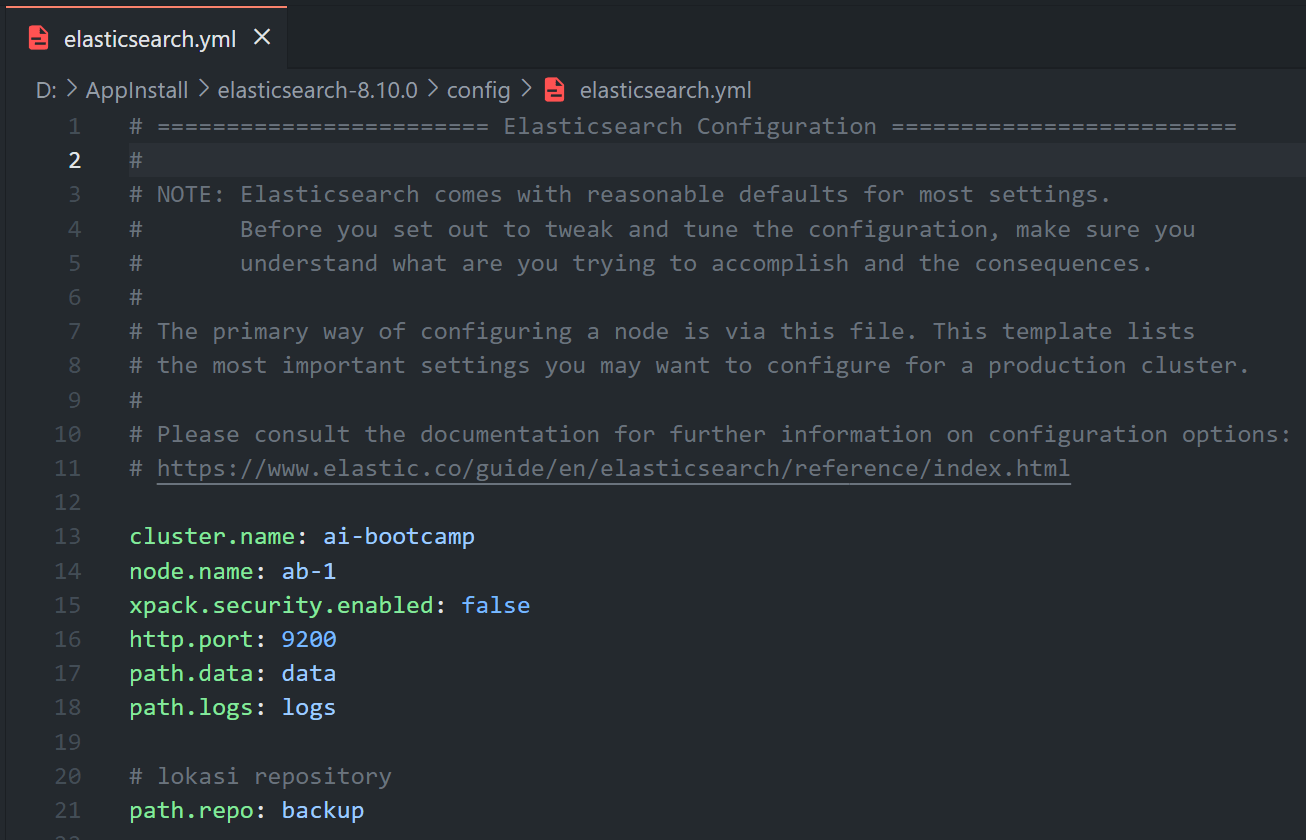
To create a repository, you use the library’s intercom system (Elasticsearch’s API) and make an announcement like: “Please set up a new repository in room <nama_repository>.” In API terms, this would be: PUT _snapshot/<nama_repository>.
Before we start practicing, install the elasticsearch package
import the packages we need
from elasticsearch import Elasticsearch
import time
import jsonCreate a connection to elasticsearch, make sure elasticsearch is running on your computer’s localhost or is running on Google Collab.
es = Elasticsearch([{'host': 'localhost', 'port': 9200, 'scheme': 'http'}])# create repository
# PUT http://localhost:9200/_snapshot/first_backup
response = es.snapshot.create_repository(
name='first_backup',
body={
"type": "fs",
"settings": {
"location": "./snapshot"
}
}
)
print(json.dumps(response.body, indent=4)){
"acknowledged": true
}# list repositories
# GET http://localhost:9200/_snapshot
response = es.snapshot.get_repository()
print(response){'first_backup': {'type': 'fs', 'settings': {'location': './snapshot'}}}Membuat Snapshot
Continuing with our library analogy, creating a Snapshot is like deciding to make photocopies of all the books or only specific ones.
To create a snapshot, you would use the library’s intercom (Elasticsearch’s API) and make an announcement like: “Please start making photocopies in room <nama_repository> and label them <nama_snapshot>.” In API terms, this would be: PUT /_snapshot/<nama_repository>/<nama_snapshot>.
You have the freedom to decide whether you want to backup the whole library (all indices) or only specific sections (certain indices). You can specify this in the Request Body.
For a more detailed guide on how to make these photocopies (create snapshots), you can visit the library’s online handbook at Elasticsearch’s Create Snapshot API documentation.
# create snapshot
# POST http://localhost:9200/_snapshot/first_backup/snapshot1
response = es.snapshot.create(repository='first_backup', snapshot='snapshot1')
print(json.dumps(response.body, indent=4)){
"accepted": true
}# get snapshot
# GET http://localhost:9200/_snapshot/first_backup/snapshot1
response = es.snapshot.get(repository='first_backup', snapshot='snapshot1')
print(json.dumps(response.body, indent=4)){
"snapshots": [
{
"snapshot": "snapshot1",
"uuid": "vUJAwg2MQeC9pdv-Ogla5Q",
"repository": "first_backup",
"version_id": 8100099,
"version": "8100099",
"indices": [
"orders",
"products",
"customers"
],
"data_streams": [],
"include_global_state": true,
"state": "SUCCESS",
"start_time": "2023-12-13T09:08:54.995Z",
"start_time_in_millis": 1702458534995,
"end_time": "2023-12-13T09:08:55.196Z",
"end_time_in_millis": 1702458535196,
"duration_in_millis": 201,
"failures": [],
"shards": {
"total": 3,
"failed": 0,
"successful": 3
},
"feature_states": []
}
],
"total": 1,
"remaining": 0
}# list snapshot
# GET http://localhost:9200/_cat/snapshots?v
response = es.snapshot.get_repository(name='first_backup')
print(json.dumps(response.body, indent=4)){
"first_backup": {
"type": "fs",
"uuid": "Oh7WOZl-T8WXVrq1CbwYhw",
"settings": {
"location": "./snapshot"
}
}
}Restore
Let’s imagine that one day, there’s an accident in the library and all the books in the ‘categories’ section get damaged. Thankfully, you have a room filled with photocopies (snapshots) of all the books. You can now Restore the ‘categories’ section using these photocopies.
Restoring is like bringing back the damaged books using the photocopies you’ve made. You don’t need to restore the entire library; you can choose to only restore the ‘categories’ section (specific index).
To do this, you would use the library’s intercom (Elasticsearch’s API) and make an announcement like: “Please restore the ‘categories’ section using the photocopies in room <nama_repository> labeled <nama_snapshot>”. In API terms, this would be: POST /_snapshot/<nama_repository>/<nama_snapshot>/_restore.
So, even though accidents can happen, thanks to snapshots and the ability to restore, your library can continue to function and serve its readers without losing valuable knowledge.
Restore Snapshot
# delete all customers
# POST http://localhost:9200/customers/_delete_by_query
response = es.delete_by_query(index='customers', body={
'query': {
'match_all': {}
}
})
print(json.dumps(response.body, indent=4)){
"took": 369,
"timed_out": false,
"total": 2000,
"deleted": 2000,
"batches": 2,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1.0,
"throttled_until_millis": 0,
"failures": []
}# search customers
# POST http://localhost:9200/customers/_search
response = es.search(index='customers', body={
'query': {
'match_all': {}
}
})
print(json.dumps(response.body, indent=4)){
"took": 67,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 0,
"relation": "eq"
},
"max_score": null,
"hits": []
}
}# close index customers
# POST http://localhost:9200/customers/_close
response = es.indices.close(index='customers')
print(json.dumps(response.body, indent=4)){
"acknowledged": true,
"shards_acknowledged": true,
"indices": {
"customers": {
"closed": true
}
}
}# restore customers from snapshot
# POST http://localhost:9200/_snapshot/first_backup/snapshot1/_restore
response = es.snapshot.restore(
repository='first_backup',
snapshot='snapshot1',
body={
"indices": "customers",
"rename_pattern": "customers",
"rename_replacement": "new_customers"
}
)
print(json.dumps(response.body, indent=4))# open index customers
# POST http://localhost:9200/new_customers/_open
response = es.indices.open(index='new_customers')
print(json.dumps(response.body, indent=4)){
"acknowledged": true,
"shards_acknowledged": true
}# search customers
# POST http://localhost:9200/new_customers/_search
response = es.search(index='new_customers', body={
'query': {
'match_all': {}
}
})
print(json.dumps(response.body, indent=4)){
"took": 17,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2000,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "new_customers",
"_id": "KbJGYowBtsOVXdO2r74I",
"_score": 1.0,
"_source": {
"index": {
"_index": "customers",
"_id": "username1"
}
}
},
{
"_index": "new_customers",
"_id": "KrJGYowBtsOVXdO2r74I",
"_score": 1.0,
"_source": {
"username": "username1",
"first_name": "Rollie",
"last_name": "Farge",
"email": "[email protected]",
"gender": "Male",
"birth_date": "1984-11-23",
"address": {
"street": "227 Eastwood Pass",
"city": "New York City",
"province": "New York",
"country": "United States",
"zip_code": "10131"
},
"hobbies": [
"Coding",
"Gaming"
],
"banks": [
{
"name": "Mandiri",
"account_number": 8949575
},
{
"name": "Mandiri",
"account_number": 9256376
},
{
"name": "Mandiri",
"account_number": 7904606
}
]
}
},
{
"_index": "new_customers",
"_id": "K7JGYowBtsOVXdO2r74I",
"_score": 1.0,
"_source": {
"index": {
"_index": "customers",
"_id": "username2"
}
}
},
{
"_index": "new_customers",
"_id": "LLJGYowBtsOVXdO2r74I",
"_score": 1.0,
"_source": {
"username": "username2",
"first_name": "Toinette",
"last_name": "Ketteridge",
"email": "[email protected]",
"gender": "Female",
"birth_date": "2000-06-07",
"address": {
"street": "48 Golf View Point",
"city": "Youngstown",
"province": "Ohio",
"country": "United States",
"zip_code": "44505"
},
"hobbies": [
"Reading",
"Coding"
],
"banks": [
{
"name": "BNI",
"account_number": 7051376
},
{
"name": "BNI",
"account_number": 9284273
}
]
}
},
{
"_index": "new_customers",
"_id": "LbJGYowBtsOVXdO2r74I",
"_score": 1.0,
"_source": {
"index": {
"_index": "customers",
"_id": "username3"
}
}
},
{
"_index": "new_customers",
"_id": "LrJGYowBtsOVXdO2r74I",
"_score": 1.0,
"_source": {
"username": "username3",
"first_name": "Lezlie",
"last_name": "Dunbabin",
"email": "[email protected]",
"gender": "Female",
"birth_date": "1978-02-28",
"address": {
"street": "4 Westerfield Circle",
"city": "Orlando",
"province": "Florida",
"country": "United States",
"zip_code": "32825"
},
"hobbies": [
"Soccer",
"Reading"
],
"banks": [
{
"name": "BSI",
"account_number": 8176225
},
{
"name": "BRI",
"account_number": 9600877
},
{
"name": "BSI",
"account_number": 4487739
}
]
}
},
{
"_index": "new_customers",
"_id": "L7JGYowBtsOVXdO2r74I",
"_score": 1.0,
"_source": {
"index": {
"_index": "customers",
"_id": "username4"
}
}
},
{
"_index": "new_customers",
"_id": "MLJGYowBtsOVXdO2r74I",
"_score": 1.0,
"_source": {
"username": "username4",
"first_name": "Jamal",
"last_name": "Habard",
"email": "[email protected]",
"gender": "Male",
"birth_date": "1977-10-29",
"address": {
"street": "01 Toban Place",
"city": "Schenectady",
"province": "New York",
"country": "United States",
"zip_code": "12305"
},
"hobbies": [
"Gaming",
"Soccer"
],
"banks": [
{
"name": "BCA Digital",
"account_number": 4429076
},
{
"name": "BCA",
"account_number": 6297767
}
]
}
},
{
"_index": "new_customers",
"_id": "MbJGYowBtsOVXdO2r74I",
"_score": 1.0,
"_source": {
"index": {
"_index": "customers",
"_id": "username5"
}
}
},
{
"_index": "new_customers",
"_id": "MrJGYowBtsOVXdO2r74I",
"_score": 1.0,
"_source": {
"username": "username5",
"first_name": "Broddy",
"last_name": "Speere",
"email": "[email protected]",
"gender": "Male",
"birth_date": "1980-10-26",
"address": {
"street": "0586 Michigan Drive",
"city": "Saint Petersburg",
"province": "Florida",
"country": "United States",
"zip_code": "33715"
},
"hobbies": [
"Gaming",
"Reading"
],
"banks": [
{
"name": "Mandiri",
"account_number": 1852753
}
]
}
}
]
}
}Close dan Open
Continuing our library analogy, the Close and Open process is like shutting down the library for renovation and then reopening it.
When we decide to restore the ‘categories’ section (or any other section), the library (Elasticsearch) requires us to close the section (index). This means that all reading and writing activities will be rejected. You won’t be able to modify or read any books in the closed section. This is important because it ensures that no changes occur while the restoration is in progress, which could otherwise lead to the books (documents) becoming corrupted.
Once the restoration process is complete, we can reopen the section using the Open Index API, allowing users to read and write again.
As for the Deleting a Snapshot process, imagine that you no longer need the photocopies (snapshots) you’ve made. You can then decide to dispose of them. You could use the library’s intercom (Elasticsearch’s API) and make an announcement like: “Please dispose of the photocopies in room <nama_repository> labeled <nama_snapshot>.” In API terms, this would be: DELETE /_snapshot/<nama_repository>/<nama_snapshot>.
Or, if you want to clean out an entire room of photocopies (repository and all the snapshots within), you could announce: “Please clear out room <nama_repository>.” In API terms, this would be: DELETE /_snapshot/<nama_repository>.
So, not only does Elasticsearch allow you to create, restore, and manage snapshots, it also provides a way to dispose of them when they are no longer needed. This keeps your system clean and efficient.
# delete snapshot snapshot1
# DELETE http://localhost:9200/_snapshot/first_backup/snapshot1
response = es.snapshot.delete(repository='first_backup', snapshot='snapshot1')
print(json.dumps(response.body, indent=4)){
"acknowledged": true
}# delete repository
# DELETE http://localhost:9200/_snapshot/first_backup
response = es.snapshot.delete_repository(name='first_backup')
print(json.dumps(response.body, indent=4)){
"acknowledged": true
}